
Why You Should Join Pinecone
Vector databases index the AI revolution.


Welcome to “Why You Should Join,” a bi-weekly newsletter for engineers highlighting early-stage startups on track to becoming generational companies.
As engineers ourselves, we know how difficult it is to pick the right startup to join. Doing your own analysis for every TechCrunch article, recruiter InMail, or VC tweet would be impossible. Let us help you out instead :)
Every two weeks, we cut through the noise and use thorough research, rigorous analysis, and inside information we’ve hustled to get to present you with an early-stage startup we believe will become a generational company. We go deeper than any other source out there to help ambitious new grads, FAANG veterans, and experienced operators find the right rocket ship to join. Sound interesting? Subscribe below and join the 250+ others that joined last month:
Why You Should Join Pinecone
(Click the link to read the full piece online)

It’s 2022, and the AI revolution is in full swing. Last year, venture capitalists invested 93.5 billion dollars into AI startups. By 2030, AI is expected to add 15.7 trillion dollars to the global economy, expanding global GDP by 14%. Already, every single app and website you use leverages AI in some way to personalize and optimize your experience. Manufacturing, retail, and financial systems across the world are all powered by AI in some way, whether you know it or not.
AI is here, and you can’t avoid it.

So how does it all work? Fundamentally, AI operates by transforming unstructured data (images, text, video) into structured data - specifically, long lists of numbers called vectors. Vectors are the structured representations of unstructured data driving the trillion-dollar AI revolution. Though they don’t get as much credit as models, they’re the critical link enabling useful applications.
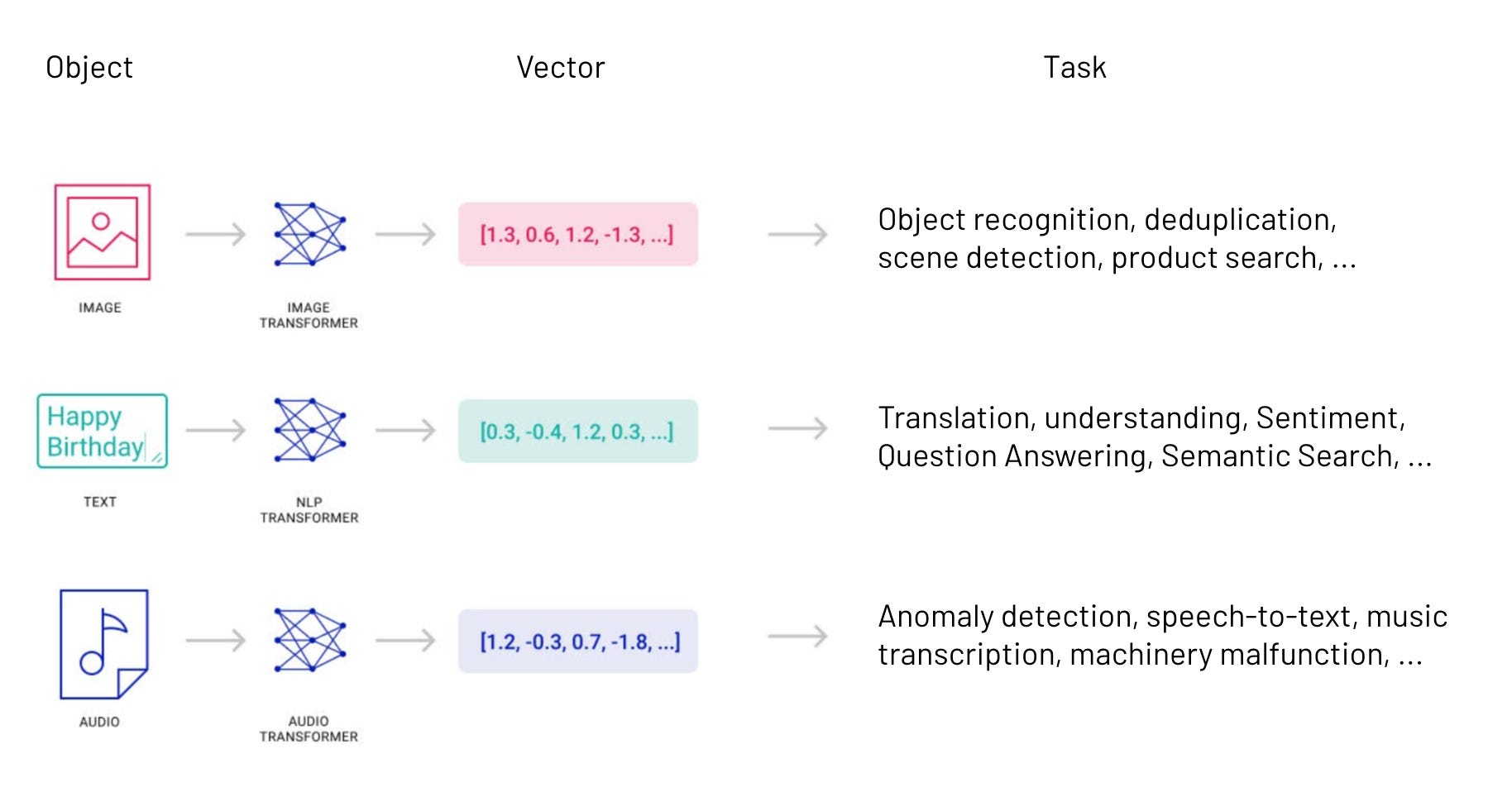
For example:
In object recognition (Instagram, Pinterest), a deep neural network will transform an input image into a vector. You can then search that vector against the vectors of known images to find close matches, telling you what the original image was.
In recommendation systems (TikTok, Amazon), a deep neural network will transform content (videos, products, etc.) into a vector. You can then search that vector against the vectors of other content to find close matches, giving you similar content to recommend.
In semantic search (Google), a deep neural network will transform query text into a vector. You can then search that vector against the vectors of indexed articles for close matches, giving you significantly better results than keyword matching (i.e. searching “pink spiky fruit” returns dragonfruit).
Google, Facebook, and Amazon already power their search engines, recommendation algorithms, and anti-fraud systems by converting billions of unstructured queries, images, and videos into vectors every day. Your company will start doing it soon, too - 80% of enterprise data will be unstructured by 2025, giving giving us 140 billion terabytes of information to vectorize and analyze. That’s a lot of vectors.
And one big headache.
See, vector data is really hard to work with. Efficiently searching through a mountain of vectors for close matches to one of interest (what a lot of the applications above boil down to) is a very difficult task. Vectors aren’t standard data - you can’t stick them in standard databases and expect standard runtimes on standard queries. Rather, they require special indexing protocols based on special algorithms.
As the AI revolution accelerates, more and more unstructured data will be converted into vectors; as a result, vector data will grow as fast as AI grows. There’s a multi-billion dollar opportunity in making it so we can store, index, and serve those vectors like traditional data. The world needs a database specifically for vectors.
Enter: Pinecone, the database built for vectors.
Background
Pinecone is the first fully managed database for vectors. Developers can use Pinecone’s API to store and query the vectors their models have generated, making it really easy to build the applications shown above.
Concretely, Pinecone creates value for engineering teams in two ways:
Simple Querying
In order to return search queries quickly, vector databases require a special class of indexing protocols based on approximate nearest neighbors (ANN) algorithms. Normally, you’d have to implement some tree, neighborhood graph, hash, or quantization-based ANN algorithm yourself to index and query your collection of vectors. Pinecone abstracts the complexity of these systems away so you can query your collection with a simple REST API.
Simple Scaling
Scaling databases across multiple machines helps them to grow larger than what can be stored on a single server. Pinecone abstracts the complexity of managing such a distributed system for you by automatically sharding and distributing itself across multiple commodity-level machines for you. In doing so, it also automatically parallelizes request handling and spreads replicas across different availability zones, improving speed and system robustness.
Pinecone offers a free plan for small projects, providing enough storage for approximately 1 million 768-dimensional vectors. For larger projects, they offer paid plans with simple hourly billing per machine. We used Pinecone to build a simple facial recognition app and found their developer experience to be exceptionally well-polished - it’s easy to see why people have been adopting it.
Pinecone launched publicly in February of 2021 and has already accrued “thousands” of users, ranging from “fast-growing startups to Fortune 500 companies.” In the past year and a half, they’ve attracted a thriving community of developers ranging from small hackers storing a few thousand vectors to large teams storing 50 billion+. Pinecone already powers the feed ranking inside of Clubhouse, the cloud infrastructure alert management system at Expel, the semantic search inside of Mem, and different systems in Gong, Course Hero, and Klue.
We’re told that Pinecone is also being used to power a facial recognition system for cows on a farm. Truly, there’s no industry that AI hasn’t touched.

Pinecone was founded 2019 by Dr. Edo Liberty, who was previously Head of Amazon AI Labs and led the development of Amazon’s popular SageMaker and ElasticSearch offerings. Edo is also the author of over 75 papers and patents and holds a Ph.D. in computer science from Yale.
Pinecone raised a 28 million dollar series A in 2022 led by Menlo Ventures. They previously raised a 10 million dollar seed round in 2021 led by Wing Venture Capital. The company is also backed by Bob Muglia (ex-CEO of Snowflake) and Bob Wiederhold (ex-CEO of Couchbase).

Pinecone has developed an incredible product: it’s proprietary indexing algorithms are feats of software engineering, completely abstracted away by the exceptional developer experience they’ve designed. They’ve got a stacked team of engineers, investors, and advisors continually improving the product, and a rapidly growing audience of developers.
But that alone doesn’t make for a category-defining company.
In this piece, we’ll dig deeper to show why Pinecone is on track to becoming such a business. We’ll look at how they’re targeting a massive, globally important market. We’ll look at how they’re well-positioned to become a leader in that market. We’ll look at how they stack up against the competition, and why their team is perfect to execute on this opportunity. And we’ll do it all as thoroughly as we can.
Ready? Let’s begin.
Opportunity
We’ll begin our analysis of Pinecone like we do for all of our companies, from a first principle:
In order for a company to become massive, it must become a leader in a massive, growing market.
Many companies with clear product-market fit don’t become truly massive because they don’t meet this condition. Thus, we must establish two things:
Pinecone operates in a massive, growing market.
Pinecone will become a leader in that market.
A Massive, Growing Market
Pinecone operates in the market for vector databases; they make money from other companies looking to build applications on top of vector databases. If the value generated by applications uniquely enabled by vector databases is large, then the market for vector databases will also be large.
We believe that the market for vector databases is massive because the low-latency vector search they uniquely enable powers a ton of important applications, each with massive markets of their own. These applications include:
Image Recognition
Applications leveraging image recognition (Instagram, Pinterest) work by using neural networks to convert images to vectors. You can then search that vector against the vectors of known images to find close matches, telling you what the original image was. Image recognition has applications in security and surveillance, medical imaging, visual geolocation, facial or object recognition, barcode reading, gaming, social networking, and e-commerce. The image recognition market is set to be worth 109.4 billion by 2027.
Text Analytics
Applications leveraging text analytics like semantic search, sentiment analysis, and translation (Google, Discord) work by using neural networks to convert strings into vectors. You can then search that vector against the vectors of indexed articles for close matches, giving you significantly better results than keyword matching. The text analytics market was worth 5.8 billion in 2020 and is set to reach 29.4 billion in 2030.
Recommendation Engines
Applications leveraging recommendation engines (TikTok, Twitter, OkCupid) work by representing content as vectors. You can then search that vector against the vectors of other content to find close matches, giving you similar content to recommend. The recommendation engines market was worth 2.12 billion in 2020 and is set to reach 15.13 billion by 2026.

We personally prefer euclidian distance ;) Anomaly Detection
Applications leveraging anomaly detection (Visa with fraudulent transactions, Expel with cyberattacks) work by converting events into vectors. You can then search that vector against the vectors of other events to see how common it is; if there aren’t many matches, something unique probably happened. The anomaly detection market is set to be worth 8.6 billion by 2026.
Chatbots
Applications leveraging chatbots (Ada, Wysdom) work by converting user questions into vectors. You can then search that vector against the vectors of known questions to find close matches, telling you which answers to provide. The chatbot market was worth 2.9 billion 2020 and is set to be 10.5 billion by 2026.

Again, all of these applications are built off of the fast vector-search capabilities that vector databases like Pinecone provide. Since the applications for Pinecone’s technology are so expansive, the direct market for Pinecone’s technology must be as well. In fact, by sitting at the bottom of this stack of AI-enabled applications, Pinecone actually indexes the rise of applications based on unstructured data.
In a similar vein, we believe this to be a growing market for the following reasons:
The applications of vector search are growing quickly. The markets for:
Image recognition will grow at a CAGR of 18.8% through 2026.
Text analytics will grow at a CAGR of 17.8% through 2026.
Recommendation engines will grow at a CAGR of 37.36% through 2026.
Anomaly detection will grow at a CAGR of 15.8% through 2026.
Chatbots will grow at a CAGR of 23.5% through 2026.
As the market for applications of vector search grow, the market for tools enabling vector search will also grow. It’s the classic picks and shovels strategy.
The space enjoys the presence of compelling tailwinds. Companies are more willing than ever to outsource their database and data science needs.
The global database software market reached 85.7 billion in 2020 and will grow at a CAGR of 9.7% through 2025 to reach 135.6 billion, ultimately reaching 189.2 billion in 2030.
The global data science platform market was valued at 95.3 billion in 2021 and will grow at a CAGR of 27.7% through 2026 to reach 322.9 billion.
As machine learning and data science continue to grow as a disciplines, more and more unstructured data will get processed as embeddings to be stored and queried in vector databases like Pinecone.
80% of the world’s enterprise data will be unstructured by 2025, growing at between 30% and 60% year over year. Insights from collections of images, audio, video, e-mails, and word processing files can’t be extracted normally since they can’t be stored and analyzed using traditional databases - as a result, only 0.5% of it is being utilized today. Machine learning models unlock the power of unstructured data by re-structuring them as vectors - we’ll then need lots of vector databases to store, index, and build off of that data.
Market Leadership
Pinecone isn’t the only vector database on the market. Milvus, Vespa, Weaviate, Qdrant, and Vald are all open-source alternatives that we’ll examine later in the piece. Even still, we believe that Pinecone will end up as a firm leader in the market. This is because:
Pinecone is building the best product in the space.
Pinecone is building the best company in the space.
The Best Product
To start, what do we mean by “best product”? It’s tempting to think that the system with the best technology (highest recall, fastest queries, lowest latency) is the best product. We don’t believe this is a productive line of thinking for two reasons:
People care about more than just the technology. If that were the case, each of MongoDB’s 33,000 customers would self-host their MongoDB clusters using the identical, open-source alternative and $MDB’s market cap would go from 20 billion to 0. The fact that open-core businesses exist at all refutes the notion that the best technology is the best product - developers care about something more.
There’s no such thing as the “best technology” in sectors with open-source alternatives. Core technologies inevitably become commoditized by open source cycles. Indeed, the top vector databases (including Pinecone) have comparable core performance. This has already happened with graph and document-based databases - the leaders in these categories had to do more than build the fastest systems.
In the world of managed developer services, you’re not selling the accuracy of your indexing algorithms or the latency of your API calls. Rather, what you’re selling is a superior developer experience: more convenient, faster setup, and with less overhead.

The system with the best developer experience is the best product, and Pinecone understands this better than the competition. They provide the best developer experience across short, medium, and long-term time horizons.
Short-Term: Time to Value
Pinecone is the only managed service on the market with a free tier. Everyone else points you to their open source project. For developers wanting to test solutions without paying, this is critical. Using Pinecone is as easy as logging in with Github, spinning up an index, and uploading your vectors. Using an open source alternative means installing and setting up everything by yourself. By providing a fully managed free tier, Pinecone’s time to value is an order of magnitude lower than anything else on the market, which is critical for the startups and high-growth organizations most often outsourcing vector search.
Short-term, engineers looking to pick a vector database can start 10x faster with Pinecone than anything else.
Medium-Term: Features and Integrations
Since Pinecone was the first to market with a managed vector database, they were also the first to start gathering feedback from paying customers. This has given them a two year head-start over everyone else in building the right features around developer experience. For instance,
Pinecone was the first to offer hybrid search in their database, allowing developers to apply metadata filters on vector queries.
Pinecone was the first to offer partial updates on vectors and metadata - other solutions require you to delete and re-upload vectors in a non-atomic fashion.
Pinecone offers best-in-class Apache Spark, OpenAI, Deepset, and Cohere integrations to make connecting your vector database with existing models and datasources as easy as possible.
Medium-term, engineers building on Pinecone can progress much faster due to their unique suite of developer-minded features and integrations.
Long-Term: Developer Relations
Pinecone does the most out of everyone in the market to support developers post-onboarding with documentation, content, and events. They’ve released an incredible set of tutorials and resources around vector search algorithms, vector search libraries, and vector search applications. For instance, their explanation of the Hierarchical Navigable Small Worlds (HNSW) algorithm is exceptional and absolutely worth checking out. We originally heard about Pinecone ourselves when some of their articles were mentioned as helpful resources in one of our Stanford computer science classes.
You can see the rest of their resources here. Through content, webinars, and events, Pinecone helps their developers to better understand the power and applications of vector databases.
Long-term, engineers building on Pinecone can leverage this understanding to build better products more easily.
From initial setup to active development to post-deployment, Pinecone provides the best developer experience out of any vector database. That gives them the best product.

The Best Company
How did Pinecone build the best product in the space? They had the best team building it. After looking at the teams of every other company in the space, it’s clear that Pinecone’s team is just way more stacked than everyone else’s. Take a look at their executive team:
Edo Liberty - Founder, CEO
Dr. Edo Liberty was previously a Director of Research at AWS and Head of Amazon AI Labs, where he was behind SageMaker, Kinesis, QuickSight, and Amazon ElasticSearch. Edo holds a Ph.D. in computer science from Yale, a B.Sc in Physics and Computer Science from Tel Aviv University, and has over 75 papers and patents published.
Ram Sriharsha - VP Engineering
Dr. Ram Sriharsha was previously VP Engineering at Splunk, head of the genomics product vertical at Databricks, a Principal Research Scientist at Yahoo, and a VP at Goldman Sachs. Ram holds a PhD in String Theory from the University of Maryland College Park and a B.S. in Electronics from IIT Madras.
Greg Kogan - VP Marketing
Greg Kogan was previously the founder of Ships at Sea, a growth consulting firm that counted Netlify ($212M raised), Domino Data Labs ($223M raised), Teleport ($169M raised), and AT&T as clients. He also runs a great blog here.
David Bergstein - Director of Product
Dr. David Bergstein was previously head of product for MATLAB and head of product for Tesseract Health ($80M raised). He holds a Ph.D. in Electrical Engineering/Photonics from Boston University and a B.E.E. in Electrical Engineering from the University of Delaware.
In addition, they’ve got the best board advisors and directors possible for the product they’re building. Key investors and advisors include:
Peter Wagner - Founding partner at Wing Venture Capital. Prior to leading Pinecone’s seed round, he invested in Snowflake’s seed round and contributed to every subsequent round of financing. Knows a lot about about scaling database startups.
Tim Tully - Partner at Menlo Ventures. Prior to leading Pinecone’s Series A, he was the CTO of Splunk, the 20 billion dollar data analytics company. Knows a lot about the needs of enterprise data science and machine learning teams.
Bob Muglia - Angel Investor and advisor. Prior to becoming one of Pinecone’s advisors, he was the CEO of Snowflake, the president of Microsoft’s Servers and Tools division, and the first product manager for Microsoft SQL. Knows a lot about designing and selling databases.
Bob Wiederhold - Angel investor and advisor. Prior to becoming one of Pinecone’s advisors, he was the CEO of NoSQL database startup Couchbase, which IPO’ed at 1.2 billion last year. Knows a lot about designing and selling databases.
Yury Malkov - Advisor. Dr. Malkov invented the Hierarchical Navigable Small Worlds (HNSW) algorithm, the hugely popular ANN algorithm at the core of Milvus, Weaviate, Vespa, and Qdrant. He is also a Staff ML Engineer at Twitter and has a PhD in Laser Physics from IAP RAS. Knows a lot about fast vector search.
Together, their team has deep expertise in ANN algorithms, production machine learning systems, enterprise database needs, product-led growth, and what it takes to engineer incredible developer experiences. This is not a team you’d want to compete against.
Concretely, having such a top-heavy team enables them to
Develop the best product and distribution strategy.
Attract the best talent in order to execute that strategy.
Talent network effects are real and provide one of the most durable long-term advantages a company can access. We think there’s a good chance that Pinecone ends up as the default location for talented operatives looking to enter the space.
Their team is especially potent given the culture of extreme focus and craftsmanship we picked up on. Not many CEOs would take calls at 1 AM while traveling halfway across the world, but Edo did with us to explain what was so special about his company. Not many engineering teams would port their entire codebase to Rust while experiencing hypergrowth, but Ram did with Pinecone’s (without dropping a single API call) to give customers the best possible experience.
It’s obvious when you’ve found a team that’s truly in love with their product and mission. Pinecone is absolutely one of them.

Competitive Landscape
We’ve spent some time analyzing Pinecone’s unique strengths as a product and company. Now, let’s have a look at how they stack up against other possible solutions for storing and searching vectors.
Vector Search Libraries
Vector search libraries help developers search through large collections of vectors for clusters or nearest neighbors. Popular ones include Google’s ScaNN (24k stars), Facebook’s Faiss (17.3k stars), or Spotify’s Annoy (10k stars).
Vector search libraries are great for vector search, but they’re not databases and have trouble at large scale. Sharding indices that don’t fit in system RAM across multiple machines for scaling and availability requirements is a big challenge for developers.
Traditional Search Libraries
Traditional search tools like Elasticsearch have begun introducing features to help with vector search as well. Based on Apache Lucene, Elasticsearch 8.0 introduced high-dimensional ANN search, and Elasticsearch 8.2 introduced hybrid search with boolean filtering. AWS’s Opensearch has similar capabilities.
The problem with these, however, is they’re also not databases. Elasticsearch just isn’t designed to be a primary data store - it’s not fault tolerant (meaning data is lost if only a few components fail) or easy to use (index sizes are pre-determined so just adding or removing vectors is difficult). They’re also much slower than purpose-built vector databases.
Self-Hosted Vector Databases
Purpose-built vector databases solve many of the previous problems. As databases, they help handle the more expressive querying requirements of many applications and the sharding challenges associated with scalable storage. Popular ones include:
Milvus - An open-source, dockerized vector database. Currently a graduate project under the Linux Foundation’s AI & Data division. 11.2k stars on Github.
Vespa - An open-source vector database. 4k stars on Github.
Weaviate - An open-source vector search engine and database with a Graphql-like query syntax. 2.5k stars on Github.
Qdrant - An open-source vector search engine and database with a REST/gRPC API. 1.9k stars on Github.
Vald - An open-source, cloud-native, vector search engine. 946 stars on Github.
Self-hosted vector databases are a big step up from vector search libraries, but they still require significant configuration from engineering teams to scale without affecting latency or availability. They don’t come with any security guarantees (i.e. GDPR or SOC 2 Type 2) and leave you with the operational overhead of maintaining additional infrastructure, monitoring additional services, and troubleshooting when things break. Solving these problems is where managed vector databases come into play.
Managed Vector Databases
Managed vector databases handle all the scaling, availability, security, and monitoring issues that developers would have to worry about normally, reducing time-to-market and maintenance costs by an order of magnitude.
Pinecone was first to market with a widely available, managed vector database. Other companies are slowing catching up, but for now, Pinecone remains one of only two options and the only option with a free tier. Here are the other options that are either currently available or coming soon:
Vespa - developed by Yahoo, they’re the only other managed service currently available without a waitlist. Compared to Pinecone, they’re a lot less developer friendly. Instead of simply uploading and querying vectors from an API like Pinecone allows, Vespa requires you to define and configure specific “Vespa application packages” for deployment to their managed cloud, a process you can read about here.
Weaviate - developed and maintained by SeMI Technologies, a Dutch startup founded in 2019 that’s raised a total of 17.2 million USD from Cortical Ventures and NEA. Weaviate as a managed service is currently waitlist-only and has no free tier.
Milvus - developed and maintained by Zilliz, a Chinese startup founded in 2017 that’s raised a total of $53 million USD from Hillhouse Capital and TBP Capital. Milvus is not yet available as a managed service, but they plan to release one eventually.
Qdrant - developed and maintained by Qdrant, a German startup founded in 2021 that’s raised a total of 2.3 million USD from 42CAP and IBB Ventures. Qdrant is not yet available as a managed service, but they plan to release one eventually.
GCP Vertex AI Matching Engine - developed and maintained by Google, this service is so difficult to use it’s hard to even call it a managed service (we included it for the sake of thoroughness). It requires developers to set up a Virtual Private Cloud (VPC) network before starting, make all requests over gRPC from within that network, and upload data using a specific input directory structure in GCP Cloud Storage buckets. The index update processes that execute when you add a vector also take a minimum of 30 minutes, making it almost unusable for an application experiencing frequent inserts. You can read more about their dubiously designed developer experience here.
Along the axis of developer experience, Pinecone significantly outclasses it’s only current competitor (Vespa) and has an almost two-year head start over everyone else. Because of this, we think that they’re strongly positioned to end up as a leader in the market.
Comparables
To make things concrete for you, we think it might be helpful to consider some other companies that have become leaders in the database space. Each of the following companies achieved a multi-billion dollar valuation by coming to dominate a specific niche of OLTP (online transaction processing) databases; if Pinecone can become The Vector Database Company™ like we expect, then they stand to do at least as well given how important vector databases stand to become.
MongoDB
MongoDB is an American software company that is one of the leaders in the document-oriented NoSQL database market. They allow you to store data in JSON-like documents with flexible schemas. MongoDB generated revenues of around 880 million USD in 2022 and currently boasts a market cap of around 20 billion.
Cockroach Labs
Cockroach Labs is an American software company that is one of the leaders in the distributed SQL database market. They allow you to store relational data in a distributed and strongly-consistent way that survives disk, machine, and even datacenter failures. They raised a 278 million USD Series F in December of 2021, valuing the company at 5 billion.
Neo4J
Neo4J is an American software company that is one of the leaders in the graph database market. They allow you to store and query data in graph form. They raised a 325 million USD Series F in June of 2021, valuing the company at 2 billion.
Redis
Redis is an Israeli software company that is one of the leaders in the dictionary-oriented NoSQL database market. They allow you to store data in a distributed, in-memory key-value cache. They raised a 110 million USD Series G in April of 2021, valuing the company at 2 billion.
The Long Term
For now, Pinecone remains laser-focused on building the best vector database possible; Edo assured us that in the short term, there aren’t any other products on the roadmap.
In the long-term, however, we think that Pinecone has the potential to be much more than a database company. Vector databases naturally sit at a critical point in the machine learning toolchain; any company with a lot of customers there would be well positioned to expand along that toolchain with new products. In particular, we can easily imagine a future where Pinecone begins offering a model hosting service, allowing them to manage the entire vector data pipeline.
In this future, Pinecone would become the first truly seamless database for storing, indexing, and serving unstructured data. Developers would upload unstructured content directly for Pinecone to vectorize, index, and partition. Then, they could query their uploads directly with additional unstructured data. One could even imagine Pinecone expanding in the OLAP (online analytical processing) database market, becoming the Snowflake or Databricks of unstructured data.
Conclusion
The AI revolution is in full swing, and much of it is powered by vector data. As a result, vector databases index the AI revolution: literally by indexing the collective output of the world’s models, and figuratively since so many AI applications are built on top of vector search. As the strongest vector database company, Pinecone will lead that revolution.
They’re hiring: Careers | Pinecone
Thanks for reading! If you enjoyed it, please remember to subscribe:
If you’re a founder or investor with a company you think we should cover, please set up a time to chat or reach out to ericzhou@stanford.edu and uhanif@stanford.edu - we’d love to hear about it :)
Thanks for the detailed research. I’m sure pinecone has a great future. What are some of the environments and integrations for pinecone?