
Why You Should Join Etched
The chip for transformers.


Some opportunities worth checking out:
Etched has built a chip that can run transformers >10x faster than GPUs. They’re currently hiring Machine Learning Researchers, Compilers Engineers, Verification Engineers, Firmware Engineers, RTL Design Engineers, interns, and more in Cupertino.
Sponsored - Our friend Anthony recently announced the third cohort of NEXT, a curated (~10% acceptance rate) community of entrepreneurial mid-career and exec-level folks thinking about their next roles. NEXT offers events with top VCs, workshops with career coaches, and a collaborative search experience with well-networked peers. We recommend joining the upcoming cohort, which starts in late Feb - mention us in your application for an expedited review.
Welcome to “Why You Should Join,” a monthly newsletter highlighting early-stage startups on track to becoming generational companies. On the first Monday of each month, we cut through the noise by recommending one startup based on thorough research and inside information we’ve received from venture firms we work with. We go deeper than any other source to help ambitious new grads, FAANG veterans, and experienced operators find the right company to join. Sound interesting? Join the family and subscribe here:
Why You Should Join Etched
(Click the link to read online).

If you’ve worked at a tech company of any sort this past year, you’ve probably heard about the recent GPU shortage.
Demand for generative AI has grown way faster than the supply of chips enabling it, and early on this left everyone wanting try it waiting in long lines.
At a private event last May, Sam Altman noted that OpenAI’s short-term product plans were severely GPU-limited, delaying the release of features like their fine-tuning API or GPT-4’s 32k context window. At an interview last September, the chairman of TSMC (the manufacturer of Nvidia’s H100 and AMD’s MI250) said they were only filling 80% of customer needs and that full demand couldn’t be met for another year and a half. As a result of all this, Nvidia was taking two to three months to fulfill new orders, companies were waiting several months to rent large blocks of GPUs, and Azure was even offering refunds to customers with unused GPU capacity so they could re-sell it to people who needed it more.
At one point, a16z estimated that demand for compute outstripped supply by a factor of 10.
There had never been a better time to be a chip company.
So naturally, every company became a chip company.
Two VCs bought 3000 H100s (at that point more than what Microsoft’s entire research arm had) for their portfolio companies to use. A crypto mining company raised 200 million of debt to buy H100s to rent, using the H100s themselves as collateral. A Colorado-based cannabis consulting company merged with a 2-month old, 0-employee data center firm called HyperScale Nexus to form a GPU hosting business that had somehow secured 30,000 H100s.
Satya Nadella, the visionary CEO of Microsoft, once observed that “every company is a chip company” (or something close).

Crucially, all these chips have been rented, purchased, or stolen to run one thing: transformers.
Transformers are the deep learning architecture used by GPTs, Llamas, Mistrals, Codexes, and Whispers — all of today’s most popular models. The architecture has become dominant in every natural language processing task (i.e. text generation, machine translation, summarization) and critical in problems as varied as computer vision (i.e. being used in stable diffusion’s encoder or in GPT-4’s vision module), audio processing (i.e. with Whisper), and protein folding (i.e. with Alphafold). Whereas before people were using specialized architectures for different tasks (i.e. CNNs for image recognition, LSTMs for text generation), transformers have sort of found their way into everything — by 2022, 70% of AI-related arXiv papers were mentioning the term.
Why this has happened is beyond the scope of this piece, but in broad (oversimplified) strokes it’s because transformers are exceptionally:
Generalizable. The attention mechanism transformers use excel at capturing relationships and long-range dependencies between elements in a sequence, something which a large class of machine learning tasks benefit from (i.e. text can be modeled as a sequence of words, images as a sequence of patches/features, audio as a sequence of MFCCs).
Scalable. Transformers scale more naturally (i.e. stacked encoders/decoders, multiple attention heads) and parallelize better than traditional architectures. This has allowed them to grow very large very quickly, compensating for their lack of task-specific specialization.
Trainable. Most importantly, transformers can learn the relationships between said elements in sequences without supervision (i.e. without labeled training data). Because of this, transformers have access to orders of magnitude more training data than their traditional counterparts, most of which require labeled examples to learn from.
The result of all this?
If software ate the world and AI is eating software, then transformers are eating AI.

The chip shortage won’t last, but its existence showed a clear demand for hardware that can run AI — particularly transformers — efficiently.
If you could build a chip that’s significantly faster and more efficient at running these models, you’d have a profound impact on the trajectory of AI, the products being built with it, and its adoption across hundreds of different industries.
You’d also make a lot of money - there’s never been a better time to be a chip company.
That’s exactly what Etched is doing.
(And yes, they are a real chip company).
Background
Etched is building a chip specifically for transformer inference.
While GPUs are great for any program that’s massively parallelizable (i.e. rendering engines, particle simulations, deep neural networks), Etched’s chip can only run one thing — transformers.
The chip, called Sohu, can run many different types of transformers (i.e. ones with different sizes, different modalities, different attention mechanisms, different activation functions, different masking systems, different encoding schemes, different sampling methods), but it can’t train them or run unrelated models like LSTMs or DLRMs. As a result, while it’s not as specific as chip that’s been hardcoded to run a specific program (i.e. an ASIC that can only run Llama 70B or SHA256), it’s also not as flexible as a GPU that can be programmed for general computation (i.e. Nvidia GPUs using CUDA).
Why is this level of abstraction in particular valuable?
Well, transformers and their applications might be the fastest growing category in software today, but existing chips are hardly optimized to run them — as we’ll explore later, only roughly 4% of an H100’s transistors are being used for actual matrix math during inference. At the same time, new and better models are coming out so frequently it’d be unwise to optimize your design around any one of them in particular. As a result, optimizing at the architectural level makes the most sense - by doing so, you can keep enough flexibility to run today’s best models while also getting a major performance boost over today’s best chips.
Big emphasis on performance boost.
While we’re unable to share performance figures publicly, we’ve gone into the weeds and have seen that on models like Llama 70B in full FP16 precision, Sohu is at least an order of magnitude better than today’s chips. This is with respect to things like:
Throughput, generating more tokens per second.
Latency, reducing the time-to-first-token.
Cost, lowering the cost per token.
We’ll go into more depth on where this performance comes from, but the upshot is that Sohu can run today’s most popular models faster than anything else. We’ve seen Sohu’s verified throughput metrics on Mistral 7B, CodeLlama 34B, Whisper V3, OPT-175B, CodeGen 16B, and many other models, and they are dramatically better than what’s out there today.
Beyond serving existing models faster, the remarkable three-pronged throughput/latency/cost improvements Sohu enables will unlock entirely new classes of applications, both technologically and economically. Imagine:
Real-time voice assistants with far lower latency and no compromise on output quality.
Better pair programmers that can search and compare many possible code paths in parallel.
More sophisticated agents and even swarms/ensembles of agents that can solve problems together.
To make developing and deploying such applications easy, Etched plans to release a complete server system and software stack with Sohu. This is to make it easy to port models on to their hardware.
We’ll go deeper on their product and GTM strategy below, but the upshot is they’ll be selling this package to companies that run their own servers (i.e. hyperscalers like AWS, foundation model companies like Anthropic, or recently-pivoted cannabis companies like Hyperscale Nexus).
Etched was founded in 2022 and, while we can’t share specifics, has accomplished quite a bit in their brief 18 months of existence. According to the Information, they’ll be announcing their chip later this year — we’re very excited.
The company was founded by Gavin Uberti and Chris Zhu, two Harvard dropouts. Gavin previously developed the ARM Cortex-M backend for Apache TVM (an open source deep learning compiler stack) and Chris previously did research in combinatorics and high performance computing. Joining them are a team of highly experienced chip designers:
CTO Mark Ross was formerly CTO of Cypress Semiconductor (acq. 9.4 billion) and has shipped 5 systems that did over a billion in revenue.
VP Hardware Engineering Ajat Hukkoo was previously VP Engineering for Intel’s Custom Silicon Group and through his career has shipped over 300 million chips to production.
Chief Architect Saptadeep Pal was previously Co-Founder/Principal Engineer at Auradine (one of America’s largest bitcoin mining system producers) and did chip architecture research at Nvidia.
On the back of their impressive traction, vision, and team, the company raised a 23 million dollar seed round last year from Primary Venture Partners and a small group of angels.

Etched has a remarkably strong team and a groundbreaking, technically sophisticated product. Their mission is to build the hardware that will enable AGI and eventually superintelligence.
Will they be able to pull it off?
Chip companies aren’t exactly easy to build — we’re not talking about a CRUD app or a GPT wrapper here.
Well, we think they’ve got a shot.
Let’s dive deeper into why.
The Opportunity
We’ll begin our exploration of Etched like we do for all of our companies, from a first principle:
Big companies lead large, growing markets.
Many startups with great teams and solid growth don’t get very big because there just aren’t enough customers for them to grow into. As a result, we’ll want to show two things:
Etched operates in a large, growing market.
Etched can become a major player in that market.
Market Size
Companies are spending lots of money on chips that can run the latest models efficiently. As we saw earlier, demand for these chips is almost insatiable:
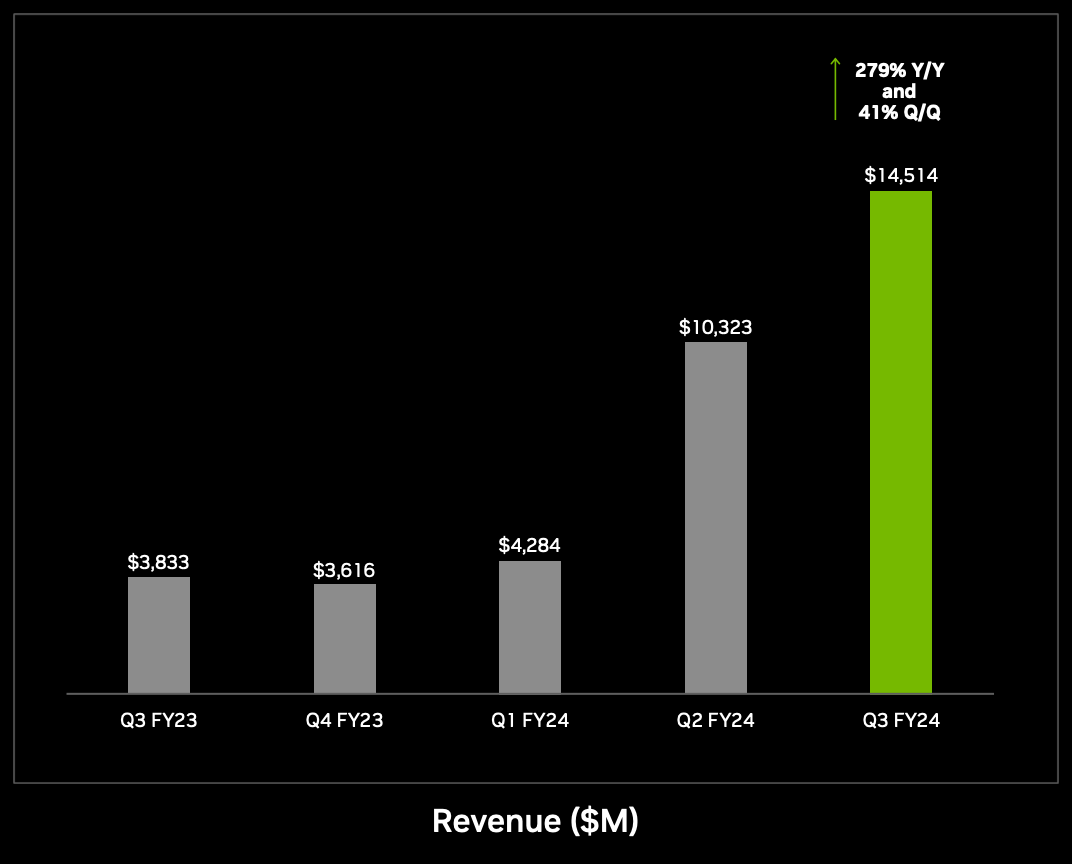
Last quarter, Nvidia sold 14.5 billion dollars worth of datacenter chips, up 279% from a year ago. Jensen Huang, Nvidia’s founder and CEO, predicts $1 trillion will be spent upgrading data centers for AI over the next 4 years.
Last year, one out of every three dollars invested in startups went to an AI company. Despite startup funding being down 30% overall, AI startups still raised a collective $50 billion, 9% more than the $45.8 billion raised in 2022. Much of that has been earmarked for compute - for some companies, up to 80% of total capital raised.
Hyperscaler cloud capex continues to grow, now largely driven by buildouts of AI capacity. By 2025, Microsoft/Amazon/Google are projected to spend a collective $120 billion annually on new data centers. Meta is aiming collect some 350,000 H100s by the end of 2024, which at a conservative 25k each is almost $9 billion from them alone.


Given this, the promise of any business that can build a more performant chip is clear. ChatGPT and the products built on it are some of the fastest growing pieces of software ever — any chip that can run them faster is going to see enormous demand.
The real question is whether such a chip can be built.
We’ll keep this section short and spend most of our time answering that question instead.
Execution
To better understand whether Etched can build the business they’re envisioning, we'll need to answer three questions, each on a different topic:
Science - is a chip like Sohu possible?
Engineering - what progress has Etched made building it?
Go-to-market - once ready, how will adoption work?
We’ll examine these questions one at a time, looking at everything from the principles behind hardware acceleration to common practices for simulating chip performance.
As a quick disclaimer, remember that all of this will remain heavily oversimplified — due both to the constraints of our medium and the confidential nature of certain details. We’ve done our best to be thorough, but you’ll have to read a textbook (or join Etched) if you want to know how this stuff really works :)
The Science
Most of us have some intuition that you can trade flexibility for performance, but we’d like to start by building a more concrete understanding of how this works.
Given a fixed amount of silicon, how do you make a chip that executes a program as quickly as possible?
Well, every program is just a sequence of instructions. These instructions are processed by processors (cores), each of which have three parts:
A fetch/decode unit that determines which instruction to run next.
An execution unit (ALU) that performs the operation described by that instruction.
A context unit (registers) that stores the state (inputs/outputs) needed to perform that operation.
The simplest processors execute one instruction per clock cycle.
How do we speed this up?
While you can get fancy with systems to minimize the number of instructions executed or the latency per instruction (i.e. branch prediction, out-of-order control logic, memory pre-fetching), for programs with parallelism, the simplest answer is also the most effective: process more instructions at once.
The central principle behind GPUs is trading fast workers (i.e. a few cores with fancy behavior) for more workers (i.e. many cores with simple behavior). For instance, compared with CPUs, GPUs have:
More cores. The 10th Generation Intel “Comet Lake” i9-10900K CPU has 10 cores, each with their own fetch/decode, execution, and context units. In contrast, the Nvidia V100 GPU has 80 SM modules (which you can think of as cores), while the GeForce RTX 4090 has 144. You can actually see these in die shots of the chips.

Die shot of the i9-10900K CPU. Source. 
Die shot of the V100 GPU, with a single SM “core” circled. 
Die shot of the GeForce RTX 4090 GPU, with a single SM “core” circled. More execution units. Imagine you’d like to execute the same instruction on 8 different pieces of data. Instead of fetching and executing that instruction 8 different times over 8 different clock cycles, a core with 8 execution units could simply broadcast that instruction to those units where it can be executed in parallel. This pattern is called single instruction, multiple data (SIMD), and here it lets us go from 8 clock cycles to 1.
GPUs leverage this to further improve throughput per core. For instance, each SM “core” on a V100 has 4 16-wide f32 execution units, meaning it can handle a total of 64 f32 MUL-ADD instructions per clock cycle. This means that across 80 SM modules, we have a total of 64 * 80 = 5,120 execution units (CUDA Cores, using Nvidia’s terminology) handling 5,120 pieces of data per clock cycle. The H100 has 14,592 such execution units across 114 SM modules. That’s a lot!

Diagram of a V100 SM module. Source.



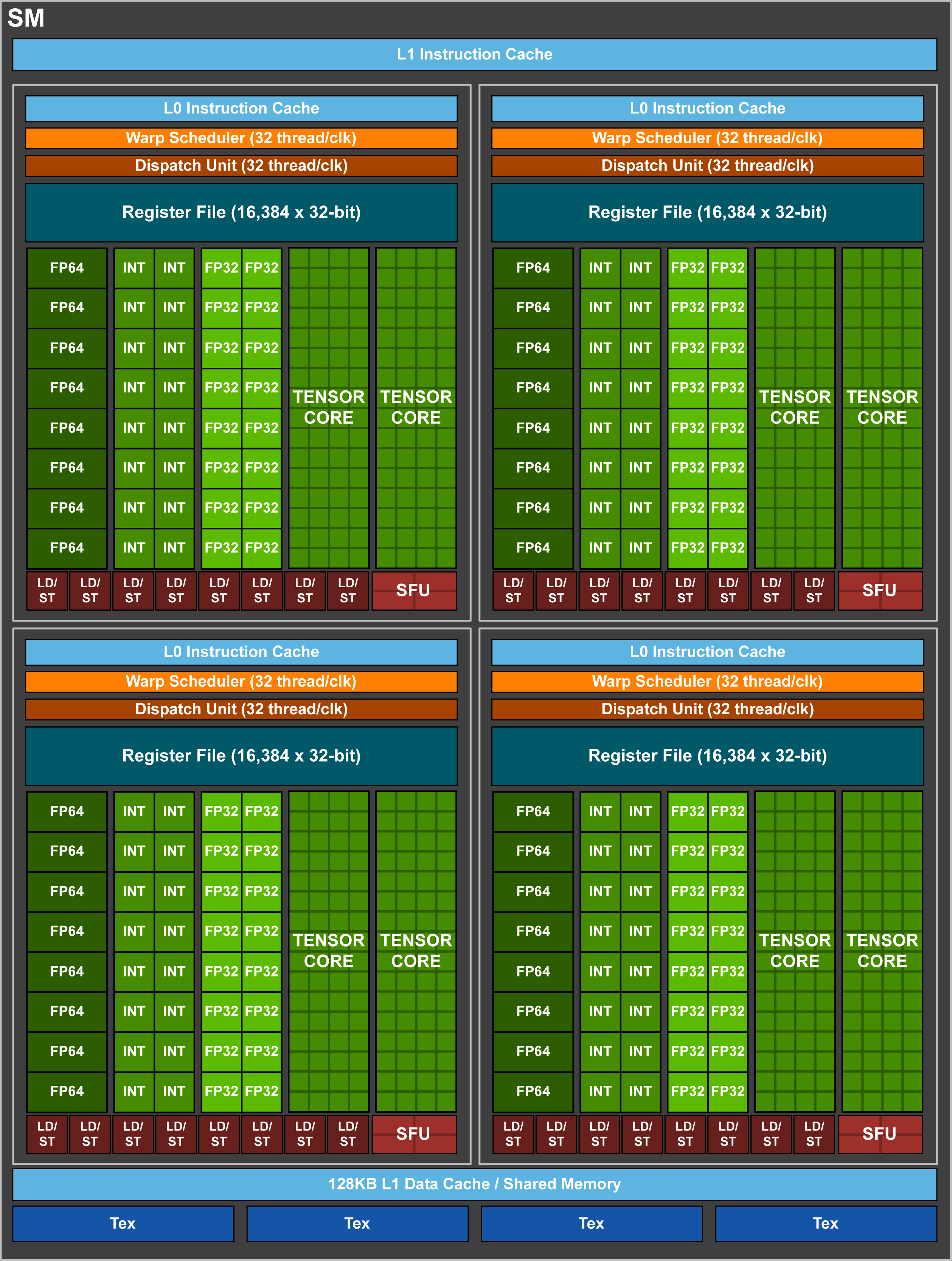
There are other things GPUs do to keep things running quickly. For instance, they use sizable caches and significant multithreading (having multiple execution contexts that execution units can hotswap between) to hide memory access latency — dead time while the right data is being loaded into the right execution context. They also have specialized execution units for certain types of computations — the V100, for instance, has specialized tensor core execution units alongside its more general CUDA core execution units.
The upshot, though, is that GPUs trade more sophisticated behavior per core for having more execution units overall (cores, ALUs per core). This makes them much faster for applications with sufficient parallel work to utilize all available execution units. In cases where there isn’t though, CPUs and their fancier cores are actually faster (i.e. w/ branch prediction, memory pre-fetching, broader instruction sets) and more versatile (i.e. capable of handling interrupts, virtualization, different privilege levels). You wouldn’t want a GPU to run your operating system, but they’re hard to beat for applications like deep learning or fluid simulations.
Sohu takes these principles up a notch.
Sohu
GPUs are optimized for parallel computation, but they aren’t perfect. When it comes to running transformers, some quick back-of-the-envelop math (original credit to Chipstrat) shows there’s still opportunity for improvement:
Taking a top-down approach, let’s estimate how much we can optimize the runtime of a popular model like Llama 70B. Running Llama has two steps: loading it into memory and doing a forward pass (the math).
Llama 70B has 70 billion parameters, which quantized at FP8 (one byte per parameter) is 70 gigabytes in total. Running the model on 4 H100 NVLs (each with a memory bandwidth of 3.9 TB/s), it should take 70 / (3900 * 4) = ~4.5 ms to load the model into memory.
Most neural network operations are memory limited rather than math limited, meaning it takes longer to access memory than to perform the actual computations. To be generous, we can upper bound it and say the forward pass takes the same amount of time as the loading step, or ~4.5 ms.
In theory, then, it should ideally take ~9 ms to run Llama 70B from scratch with this setup.
In practice, however, Nvidia reports it takes 109ms (time-to-first-token, FP8 quantized Llama 70B on 4 H100 NVLs with 2048-token input length). There’s an extra 100ms of latency being added somewhere - but where?
Taking a bottoms-up approach, let’s see if we can optimize the design of today’s chips directly. Gavin, Etched’s CEO, has said only ~4% of an H100’s transistors are being used for the matrix multiplications driving LLM inference. Is this true?
Humor us for a second. If 100% of an H100’s transistors were being used for matrix multiplications, how many FLOPS would it produce? Nvidia’s tensor cores use fused multiply-add circuits (FMAs) for matrix multiplication, each of which does two operations per clock cycle — an addition operation and a multiplication operation. Running at a base clock speed of 1590 MHz, a single FMA would produce 1590 MHz * 2 FLOPS = 3.18 GFLOPS. Since state-of-the-art FMAs take roughly 10k transistors to construct, converting all 80 billion of the H100’s transistors to FMAs would give us 8,000,000 FMAs in total, generating a collective 8,000,000 * 3.18 GFLOPS = 25,440 TFLOPS.
In practice, however, Nvidia reports the output of the H100 at 990 TFLOPS (without their assumption of sparsity), meaning we only have 990 / 25440 = ~3.8% of the FMAs we’d ideally like. This suggests that much of the H100’s silicon area is stuff besides execution units - but what?
This “bloat” comes from many places. Software-wise, things like thread management and resource contention, CUDA kernel setup and teardown, inefficient memory access patterns, and superfluous control logic add overhead. Hardware-wise, space we’d otherwise use for execution units must be saved for things like network infrastructure, which allows data to move from any one SM module to any other.
The upshot is that since GPUs are optimized for general parallel computation, there’s a lot of hardware/software overhead that’s not relevant to transformer inference. Since Sohu is designed specifically to execute transformers, it’s able to replace much of that with more relevant compute units, driving that 4% up and that latency down.
More concretely, Sohu leverages several attributes of transformer inference workloads to improve performance. These include:
Deterministic data flow. In contrast to say a particle simulation, AI models are deterministic — they have no “if statements” or conditional branches.
As a result, with transformer workloads you know when and where each piece of data needs to be ahead of time. You can orchestrate memory access patterns so that the right data is in the right place at the right time, which removes the need for a lot of flexibility-related overhead. For instance, you can cut branching and other control flow related blocks, the L1-L3 cache hierarchy (you know in advance when you’ll need each piece of data), infrastructure to pass data between different cores, and much more. In their place, Sohu has added many more execution units.
The nature of attention. Attention is a computation between two operands dependent on prior sequence data (i.e. query matrix Q and key matrix K are both functions of input sequence x), and Etched has proprietary hardware to do this without using standard GEMM (general matrix multiplication) engine architectures. Sohu uses less surface area to compute attention than traditional chips, which allows it to include many extra execution units.
Relevant data types. Transformers only use low precision numbers so there’s no need for fp64 compute units like the H100 has. Sohu has removed execution units of data types that aren’t commonly used in transformers, allowing it to include more execution units for the ones that are.
Etched also leverages other magical things like activation approximation (allowing Sohu to compute popular and fully custom activation functions with less silicon area than GPUs/TPUs), improvements around large scale batching, and cleverly optimized memory access patterns around data re-use to make things more efficient.
Believe us, they’ve filed lots of patents.

The Engineering
Now that we understand the general principles driving Sohu’s performance, how much progress has Etched made actually building it?
We’ve gone into the weeds with them and while we can’t share the details on their progress, two things are clear: they’re pretty far along and they’ve been exceptionally rigorous about verifying Sohu’s performance/functionality.
Digging deeper on the second, you might still be wondering where the performance figures from earlier came from. How can we treat them with any degree of confidence when Etched hasn’t actually produced a chip yet?
Well, contrary to popular belief, you can actually simulate the performance of a chip (to a high degree of confidence, within several percentage points) before fabricating it for real. This is standard practice in the chip industry, and at a high level involves a few steps:
Design. Chip designers will describe the digital circuit they’d like to make in code using a hardware description language (HDL) like Verilog or VHDL. At the register-transfer level (RTL) of abstraction, the circuit is described in terms of registers (storage elements) and the transfer of data between these registers, which includes logical operations, arithmetic operations, and control flow. This code doesn't represent the physical circuit components directly but describes how data moves and is transformed within the system.
Simulation. Once the RTL description is complete, simulation tools are used to verify the logical correctness of the design. Tools like Verilator, Synopsys VCS, or Cadence Xcelium are used to compile the HDL into a cycle-accurate behavioral model, which you can then apply different sets of inputs against. That way, designers can ensure their design behaves as intended before moving forward.
Synthesis. Finally, designers can use a synthesis tool like Synopsys Design Compiler or Cadence Genus to translate the RTL description into a gate-level representation, which maps the RTL constructs to actual hardware elements like logic gates and flip-flops. This process also involves optimizations to meet the desired performance, area, and power specifications. After this, a timing analysis can be done to ensure that the circuit meets the required speed performance. For instance, critical path analysis might be performed, where the longest paths data might travel within a clock cycle are examined to ensure they can be traversed within the given clock period.
While there might be other steps after (i.e. formal verification to mathematically prove specifications are met under all possible inputs, mapping the synthesized design to a physical layout on silicon, checking for possible physical issues like electromigration or antenna affects), at a high level this is how chip designers verify the functionality and performance of their designs before fabrication.
Etched has done similar things to verify the functionality and performance of their designs, but they’ve also used a few less conventional testing methods on top. While we can’t detail them here, here’s one example of just how meticulous they’ve been.
Transformers include several numerical operations beyond FP16 multipliers — think activation functions, up/downcasting blocks for conversion, accumulators for keeping track of layer norm means/standard deviations, and sine and cosine blocks for rotary embeddings. Not all of these functions are covered in the IEEE-754 standard, and as a result many can be computed in slightly different ways. To ensure that Sohu behaves the same as GPUs at the block level, Etched has run exhaustive simulations of each and every one of these math blocks to make sure the computed numerics are equivalent to those of popular GPUs.
This team means business.

The Business
Once Etched’s chip is ready, how will they go about taking it to market?
Sohu might be the best chip in the world for transformer inference, but companies wanting to use it will need more than just that. Most aren’t interested in building their own boards to mount the chip, servers to hold the boards, or firmware to run the servers. They definitely aren’t interested in writing their own compilers so their models can run on a new piece of hardware.
Because of this, Sohu will be sold as a complete system, accompanied by a software stack letting users port their models over in just a few lines of code.
From the end-user’s perspective, this software part is critical.
One reason Nvidia’s chips have been so popular for so long is the dominance of CUDA, which is the API Nvidia developed allowing their GPUs to be programmed for non-graphics workloads. Since being released in 2007, CUDA has become something of a moat for Nvidia - its popularity means lots of developers are familiar using it and that many tools/libraries have been built on top of it.
As a result, the switching cost of adopting any non-CUDA chip is quite high. Since CUDA is proprietary, developers would have to learn whatever their new chip’s version of CUDA is so they could port their model over. As you can guess, this is quite difficult.
Etched, however, doesn’t suffer from this problem. Since Sohu only runs transformers, they’ve been able to write a simple transformer-specific compiler making it easy for users to port models over to their chip. This would be a lot harder for chips capable of general computation, but constraining the problem from running arbitrary code to running just transformers makes developing said software easier.
As a result, adoption from the thousands of companies running transformer inference should be easier. The sales cycle is no longer a pure hyperscale play: there are plenty of startups, scaleups, clouds, and enterprises doing on-prem compute that are looking to optimize their cost and latency.
Long-term, as models become more powerful and the cost to get state of the art increases, the time between major models will increase also. As this happens, Etched may develop ever-more specialized chips, eventually becoming the model-specific AI company as well.
Team
Etched wants to build the world’s best chip for transformer inference. More than that, they want to create the hardware enabling AGI and eventually superintelligence.
It’s an ambitious mission, but they’ve built a team with the incredible software and hardware engineering experience needed to pull it off.
Consider a sampling of their roster:
Gavin Uberti - Co-Founder, CEO
Gavin was previously a Software Engineer at OctoML. Before that, he was an Algorithms and Backend Engineer at Coursedog. Earlier, he was a Software Engineering Intern at Xnor.ai. He dropped out of Harvard while pursuing a BS and MS in Computer Science.
Chris Zhu - Co-Founder, Director of Compilers
Chris was previously a math and HPC researcher at Harvard University. Before that, he was a Software Engineering Intern at AWS. Earlier, he was a Software Engineering Intern at AvantStay. He dropped out of Harvard while pursuing a BS in Computer Science and Mathematics.
Mark Ross - CTO
Mark was previously the Co-Founder and VP of Engineering at Striiv. Before that, he was the CTO at Cypress Semiconductor (acq. 9.4 billion). Earlier, he was a Senior Director at Cisco. He started his career as an Architect at Sun Microsystems and holds a BS and MS in Electrical Engineering from Stanford University.
Robert Wachen - COO
Robert was previously a Co-Founder at Prod, a startup accelerator. Before that, he was the Co-Founder and CEO at Mentor Labs, which was acquired by Crimson Education. He dropped out of Harvard while pursuing a BS in Decision Science.
Ajat Hukkoo - VP Hardware Engineering
Ajat was previously the VP of Engineering for Intel’s Custom Silicon Group. Before that, he was a Director of Engineering at Broadcom. He holds a B.Tech in Electrical Engineering from IIT Bombay.
Saptadeep Pal - Chief Architect
Saptadeep was previously a Co-Founder and Principal Engineer at Auradine (one of America’s largest bitcoin mining system producers, valued of 500 million). Before that, he did architecture research at Nvidia. He holds a B. Tech in Electrical Engineering from IIT Patna and an MS/Ph.D. in Electrical and Electronics Engineering from UCLA.
Abhishek Chinchalpet - Principal Verification Engineer
Abhishek was previously a Verification Engineer at Elastic.cloud. Before that, he was an ASIC Design Verification Engineer at Waymo. Earlier, he was a Senior Silicon Engineer at Google. He started his career as a Hardware Engineer at Oracle and holds an MS in Computer Engineering from Texas A&M.
Reynold Leong - Founding Principal Engineer
Reynold was previously a Staff Verification Engineer at Cruise. Before that, he was a Principal Verification Engineer at Quanergy. Earlier, he was a Senior Verification Engineer at Violin Memory. He holds a BS in Electrical and Computer Engineering from UC Berkeley and an MS in Electrical and Computer Engineering from UC Irvine.
AppaRao Challagundla - Founding Principal Engineer
AppaRao was previously the SOC Chief Architect (Confidential Compute) at Intel. Before that, he was a Senior Design and Verification Manager at Intel.
Prasad Bolisetty - Director of Software
Prasad was previously a Software Engineering Manager at Intel. Before that, he was the Director of Software at Soft Machines. Earlier, he was a Sr. Principal System Software Engineer at Broadcom. He holds a BE in Electronics & Communication Engineering from Andhra University.
Chang-Ming Lin - Principal Engineer
Chang-Ming was previously an ASIC Design Manager at XPENG. Before that, he was a Sr. ASIC Design Manager at Silicon Motion Technology Corp., and earlier, a Design Lead at Intel Corporation. He holds an MS in Electrical and Electronics from the University of Utah.
Carson Robles - ASIC Design Engineer
Carson was previously a Hardware Engineer at Optiver. Before that, he was a Hardware Engineering Intern at Astranis. He holds a BS in Computer Engineering from Cal Poly SLO.
Hsu-Kuei Lin - ASIC Design Engineer
Hsu-Kuei was previously a Digital Circuit Designer at Meta. Before that, he was a Staff Engineer at Qualcomm. Earlier, he was a Member of the Technical Staff at NUVIA. He started his career as a Senior Hardware Engineer at Microsoft and holds an MS in Electrical Engineering from the University of Michigan.

Competitive Landscape
Etched is a transformative player in the world of AI chips, but at first glance they’re not the only player in the space. If you google “chips for AI”, you’ll find a laundry list of companies appearing to make similar bets.
Now that we’ve got an understanding of Etched’s unique strengths, let’s see how they compare against some of these competitors.
Incumbents
Nvidia controls 87% of the discrete GPU market. Second place goes to AMD, who controls about 10%. Several hyperscalers have built internal silicon teams to try and commoditize Nvidia (i.e. Google’s TPUs, AWS’s Trainium and Inferentia, Azure’s Maia), but so far all have trailed Nvidia by 6-18 months when it comes to raw performance.
Each of these incumbents produces general-purpose chips for both inference and training. As a result, they’re much slower than Etched when it comes to transformer inference. Not only that, compared to our predictions around the performance of the next few generations of GPUs, Etched should still be more performant.
So why won’t Nvidia just clone Sohu?
You can never fully rule out this possibility (startups, man), but we can think of a few reasons they won’t:
Etched is making a bet that a transformer-like architecture will remain dominant for the next few years. This is a risky proposition: model architectures have changed before, and while transformers have become industry standard, potential rivals emerge all the time. Nvidia’s dominance in the status quo means they have zero incentive to take a similar risk.
CUDA, Nvidia’s API to program their GPUs for general computation, is one of their strongest moats. It’s durability stems from its sophistication, and its sophistication stems from the general purpose nature of Nvidia’s GPUs. Building an architecture-specific chip would negate much of CUDA’s importance/utility, eating into their own moat. Nvidia’s dominance in the status quo means they’re disincentivized to take a similar risk.
Not to mention, building a chip like Sohu isn’t exactly trivial — Etched has made a number of (patented) technical breakthroughs, so even if an incumbent tries they’ll be starting from behind.
Plus, if Etched is successful, general-purpose chips won’t go anywhere — H100s and TPUs will still be used for training and for non-transformer workloads.
Startups
There are a number of startups that are also building general-purpose AI chips for both inference and training. These include:
Cerebras, which has raised over 720 million. Instead of slicing a silicon wafer into lots of smaller, individual chips like most companies, Cerebras has turned the entire wafer into one giant chip with lots of extra processing power and on-chip memory. It’s an amazing feat of engineering — the idea was to reduce data transfer/latency bottlenecks by fitting the entire model into on-chip memory (i.e. the WSE-2 has 50GB of on-chip SRAM). Unfortunately, they didn’t anticipate how large modern LLMs would get, which has led to some challenges.
SambaNova Systems, which has raised over a billion. Their latest chip, the SN40L, is a general purpose AI accelerator with a unique part-HBM, part-GDDR memory system. It leverages Sambanova’s Reconfigurable Data Unit (RDU) architecture, which essentially allows you to configure the physical flow of data across the chip as a means of minimizing unnecessary data movement. It’s sold as part of a full stack AI platform, complete with server systems and software.
Graphcore, which has raised over 760 million. Their flagship product is a chip they’re calling the Intelligence Processing Unit (IPU). The IPU unfortunately hasn’t lived up to its promise, and the company is struggling financially. Microsoft, one of their key investors and early customers, pulled out of a deal for their processors last year.
While these companies have raised lots of money and shipped chips, they’ve struggled to achieve adoption. NVIDIA’s GPUs often ended up being more performant and the software switching costs often ended up being too high. As a result, several of these companies have pivoted to a “model-as-a-service” approach, abstracting the software and hardware away from the end customer and offering more of a white-glove ML service.
There are also a number of startups building general-purpose chips for inference. These include:
Groq, which has raised over 360 million. Their main product, the Language Processing Unit (LPU), is a smaller, cheaper chip that can be chained together in pods of 264 (in the future, 4,128) to create servers for inference.
d-Matrix, which has raised 154 million. Their product, Corsair, is an inference platform that’s based on chiplets - smaller, specialized chips that can be combined to form a comprehensive integrated circuit. The Corsair’s chiplets, called Jayhawk IIs, further feature a digital in-memory compute (DIMC) architecture designed to minimize unnecessary data movement.
Kneron, which has raised over 190 million. They’re building AI chips optimized for edge devices, particularly self-driving cars. They’re not focused on data centers or LLM inference and aren’t directly competitive with Etched.
Sima, which has raised over 200 million. Like Kneron, they’re also building AI chips for edge devices. They’re not focused on data centers or LLM inference and aren’t directly competitive with Etched.
By only supporting inference, these chips will have better performance than more flexible AI accelerators. However, they’ll still be significantly worse than chips which have specialized on an architecture.
Etched is building such a specialized chip. By betting on transformers specifically, they run the risk that their chips will be obsolete by the time they get to mass production. If they’re right though, they’ll be the most performant chip for transformers by far.
There are a few companies that are making bets similar to Etched, but they all seem to be earlier in the process. These include:
MatX, who’s building a chip focused specifically on LLM inference. They’ve made a different bet than Etched, however, and have optimized their chip around quantization — specifically models using int4 precision. Whether models can be quantized to that level without degrading performance remains an area of active research.
Positron, who’s building a “Transformer Inference Appliance” by chaining existing GPUs together. They aren’t building their own chips yet.
Conclusion
If Etched succeeds, running transformer-based models will never be the same again. Why wait in line for GPUs when you can get >10x the performance with Sohu instead?
They’re hiring.
Thanks to Philip Bogdanov for his help with this piece.
In case you missed our previous releases, check them out here:
And to make sure you don’t miss any future ones, be sure to subscribe here:
Finally, if you’re a founder, employee, or investor with a company you think we should cover please reach out to us at ericzhou27@gmail.com and uhanif@stanford.edu - we’d love to hear about it :)
Hii
It’s the SW stack that matters. It’s not GPU vs … it’s CUDA vs ….