
Why You Should (Still) Join Pinecone
On Pinecone’s 100 million dollar Series B from Andreessen Horowitz.


Pinecone has grown significantly in the past year and is currently hiring Software Engineers, Software Engineering Interns, Product Managers, Developer Advocates, Account Executives, and more across San Francisco, Tel Aviv, and New York City — read our original piece on them here.
If you’re interested in roles with any of the companies we’ve covered (or the unreleased ones we have in our pipeline 👀), please fill out this form to join our talent network.
Welcome to “Why You Should Join,” a monthly newsletter highlighting early-stage startups on track to becoming generational companies. On the first Monday of each month, we cut through the noise by recommending one startup based on thorough research and inside information from partnered venture firms. We go deeper than any other source to help ambitious new grads, FAANG veterans, and experienced operators find the right company to join. Sound interesting? Join the family and subscribe here:
Why You Should (Still) Join Pinecone
(Click the link to read online).

About a year ago, we picked Pinecone as the second company to feature in this newsletter.
A few months ago, they announced their 100 million dollar Series B led by Andreessen Horowitz. Besides Andreessen, other new investors included ICONIQ Growth. Prior investors Menlo Ventures and Wing Venture Capital also participated in the round.
We wanted to take this chance to reflect on the original piece while exploring how Pinecone has progressed in the year since. How are they doing? Where are they now?
Let’s get into why you should (still) join Pinecone.
Background
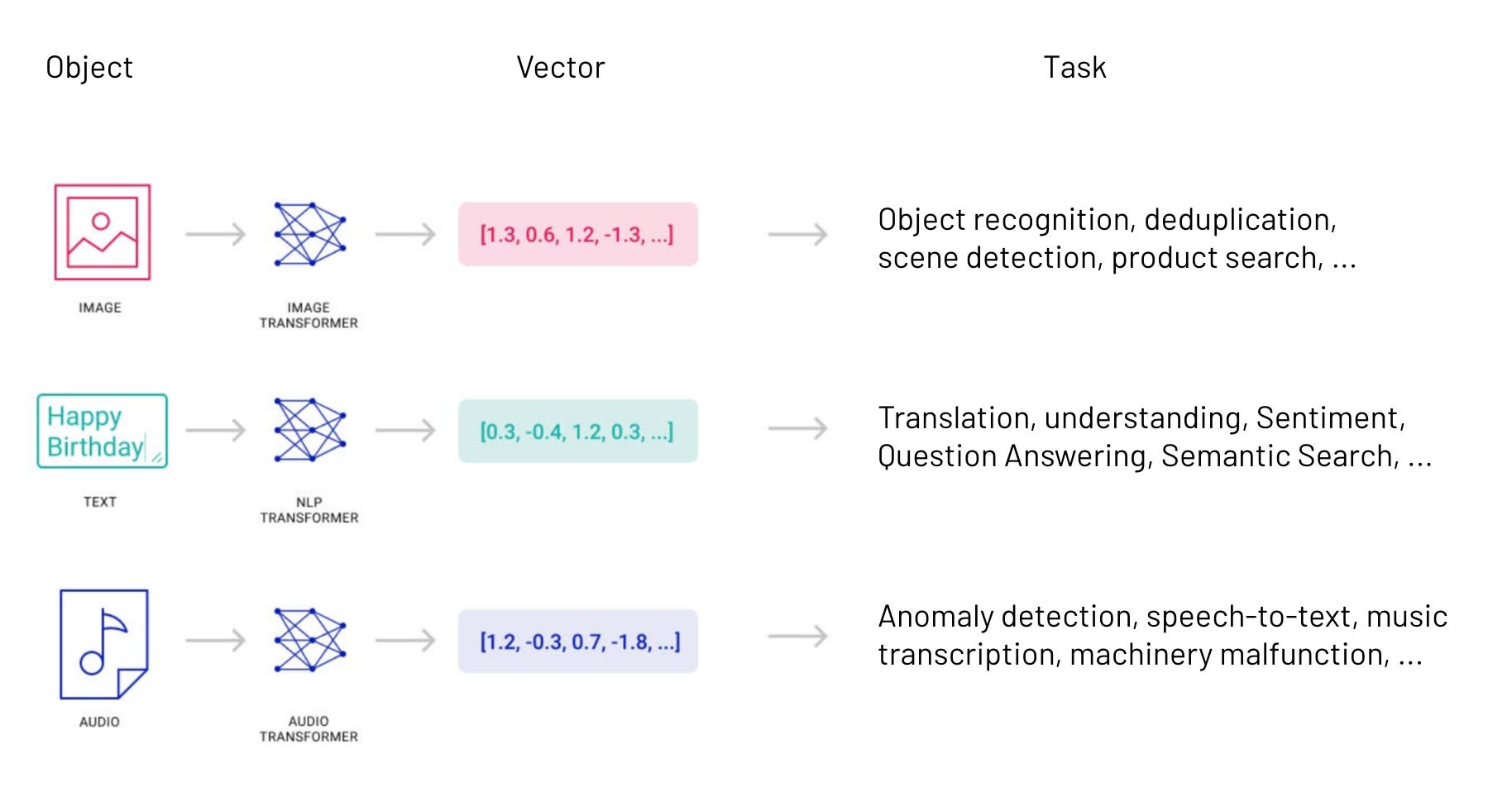
Vectors are the backbone of modern artificial intelligence.
As the universal input and output format for neural networks, you can’t use AI without also using vectors. For instance:
Sentences are converted to vectors so they can be used by language models. These power applications like semantic search, machine translation, and conversational chatbots.
Images are converted to vectors so they can be used by vision models. These power applications like object detection, facial recognition, and generative fill.
Recordings get converted to vectors so they can be used by audio models. These power applications like speech transcription, anomaly detection, and covers of classic songs by South Park characters.
If you want to work with the inputs and outputs of machine learning systems at any scale, you’ll have to get comfortable working with vectors.
The problem is, vectors are kind of hard to work with.
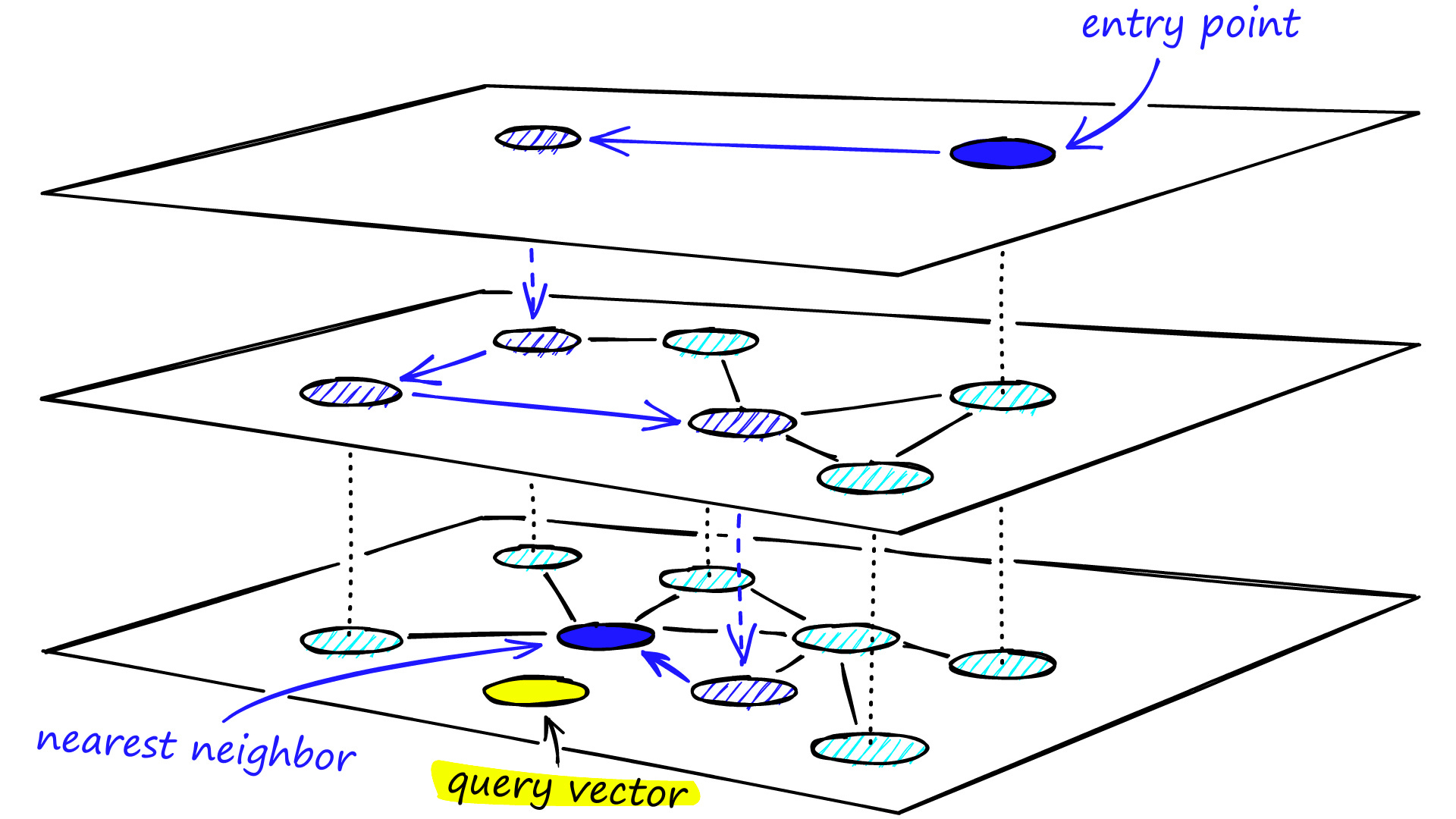
Unlike traditional data types, which we could scalably store/update/query with an arsenal of traditional databases, there was no such system for vectors. Doing something as foundational as finding the closest vector to some query vector (something chatbots often do when looking for a source to cite) was hard when you needed a result in constant time — and even harder at scale.
Traditional databases didn’t work with vector data because vector data required a completely different set of indexing algorithms:
Efficiently searching through a mountain of vectors for close matches to one of interest (what a lot of the applications above boil down to) is a very difficult task. Vectors aren’t standard data - you can’t stick them into standard databases and expect standard runtimes on standard queries. **Rather, they require special indexing protocols based on special algorithms.
In a very real sense, you could think of vectors as the first data type native to machine learning: if traditional apps were sequences of manually-defined transformations on manually-defined data structures (classes, objects), AI-native apps were sequences of learned transformations on learned data representations (vectors, tensors).
This novelty meant we needed a different set of tools to work with vectors properly, a set of tools that didn’t yet exist.
Pinecone was trying to change that.
They had built the first fully managed database for vectors, making it super easy for developers to work with this foundational new data type. Out of the box, Pinecone offered:
Simple Querying - instead of implementing your own tree, neighborhood graph, hash, or quantization-based approximate nearest neighbors indexing protocol for constant-time vector search, you could query Pinecone with a simple REST API.
Simple Scaling - instead of sharding and distributing your database yourself as you scale (a non-trivial task), Pinecone does everything for you. They also automatically parallelize request handling and spread replicas across different availability zones to improve throughput and system robustness.

Thousands of developers were already using Pinecone, ranging fast-growing startups storing a few thousand vectors to Fortune 500 companies storing over 50 billion. Pinecone was already powering the semantic search inside of Mem, the feed ranking inside of Clubhouse, the cloud infrastructure alert management system inside of Expel, and various systems within Gong, Course Hero, and Klue.
Most notably, it was being used to power the facial recognition system for cows on a farm.

It was obvious that Pinecone had built a useful product.
What was less obvious was whether they could build a massive, “category defining” business off of it.
Well, we thought they had a shot:
The AI revolution is in full swing and much of it is powered by vector data. As a result, vector databases index the AI revolution: literally by indexing the collective output of the world’s models, and figuratively since so many AI applications are built on top of vector search. As the strongest vector database company, Pinecone will lead that revolution.
Our chain of reasoning was roughly as follows.
A Large Market
Pinecone operated in the market for vector databases — they made money from other companies looking to build on top of vector databases. If the value generated by applications uniquely enabled by vector databases was large, then the market for vector databases would also be large.
We thought this was a large, growing, and important market because the low-latency vector search these databases uniquely enabled powered tons of important applications, each with massive markets of their own. These included:
Image Recognition. Applications leveraging image recognition (Instagram, Pinterest) work by using neural networks to convert images to vectors. You can then search that vector against the vectors of known images to find close matches, telling you what the original image was. Image recognition has applications in security and surveillance, medical imaging, visual geolocation, facial or object recognition, barcode reading, gaming, social networking, and e-commerce. The image recognition market is set to be worth 109.4 billion by 2027.
Recommendation Engines. Applications leveraging recommendation engines (TikTok, Twitter, Tinder) work by representing content as vectors. You can then search that vector against the vectors of other content to find close matches, giving you similar content to recommend. The recommendation engines market was worth 2.12 billion in 2020 and is set to reach 15.13 billion by 2026.
Chatbots. Applications leveraging chatbots (Ada, Wysdom) work by converting user questions to vectors. You can then search that vector against the vectors of known questions to find close matches, telling you which answers to provide. The chatbot market was worth 2.9 billion 2020 and is set to be 10.5 billion by 2026.
We clearly undershot the market for chatbots, but a win is a win.
After all, our broader thesis was that vector databases stood to index all of AI development activity — we knew that as the universal input/output format for modern AI systems, vectors were a data type anyone doing anything with AI would have to work with. That this was so difficult meant meant there was a huge opportunity for vector infrastructure startups like Pinecone to create and capture value — betting on vector databases was betting on AI development activity itself.
A Leading Product
Pinecone was the first fully managed vector database, but they weren’t the only vector database on the market. At the time of publication, the other options were Milvus (Zilliz), Vespa, Weaviate, Qdrant, Vald, and GCP’s Vertex AI Matching Engine. We wrote detailed, direct comparisons of each of these against Pinecone (as well as with vector search libraries like ScaNN/FAISS/ANNOY, traditional search libraries like Elasticsearch/Opensearch, and self-hosted vector databases like Vald) which you can read in the original piece if interested.
The upshot was that Pinecone had the best product, both technically and with regards to developer experience. For instance:
Pinecone was the first to offer hybrid search in their database, allowing developers to apply metadata filters on vector queries. Pinecone was the first to offer partial updates on vectors and metadata - other solutions required you to delete and re-upload vectors in a non-atomic fashion. Pinecone offered best-in-class integrations with Apache Spark, OpenAI, Deepset, and Cohere, which made connecting your database with existing models/data sources as easy as possible.
Pinecone was the only managed service on the market with a free tier. While everyone else pointed you to their open source project, trying Pinecone was as easy as logging in with Github, spinning up an index, and uploading your vectors. For developers wanting to test solutions quickly and without paying (i.e. the high-growth startups and teams most often outsourcing vector search), this was critical. By providing a fully managed free tier, Pinecone’s time to value was an order of magnitude lower than anything else on the market, meaning you could start 10x faster with them.
Plus, as the first company to market with a managed vector database, they had a two year head-start on the intricacies around building a managed service — the technical details, the developer experience, the enterprise-readiness.
As late as July of 2022, Pinecone remained one of only two fully managed offerings (serving databases is hard) and the only option with a free tier. It was clear they were best positioned to capture any new demand for this new class of infrastructure.
A Strong Team
How did Pinecone build the best product in the space? They had the best team building it.
Besides comparing Pinecone’s product against their competitors, we also compared the strength of their respective teams. Beyond generally being higher quality than their competitors, there were two things we really liked about the folks at Pinecone:
They had lots of experience with machine learning. This gave them knowledge of the kinds of products/workflows Pinecone would be used for and empathy for their end-users.
They had lots of experience with databases. This gave them the insight and intuition needed to build a database product and take it to market.
For instance:
Founder and CEO Edo Liberty was a Director of Research at AWS and Head of Amazon AI Labs, where he was behind SageMaker, Kinesis, QuickSight, and Amazon ElasticSearch.
VP of Engineering Ram Sriharsha was VP of Engineering at Splunk, head of the genomics product vertical at Databricks, and a Principal Research Scientist at Yahoo.
Board member Peter Wagner was previously a seed investor in Snowflake. Board member Tim Tully was previously CTO of Splunk and VP Engineering at Yahoo.
Advisor Bob Muglia was previously CEO of Snowflake. Advisor Bob Wiederhold was previously CEO of Couchbase.
In essence, we saw a market poised for enormous growth, a leading product in that market, and a stacked team focused on beating the competition.
What wasn’t to like?
For the full analysis, read the original piece here.
Growth
So how has Pinecone progressed in the year since?
Well, before even getting to Pinecone, it’s worth appreciating how much vector databases as a whole have grown. The category has raised a collective $350 million at this point, with almost 70% of that being in the last 12 months:
Zilliz raised their $60 million Series B Extension (August 24th, 2022).
Chroma raised their $18 million Seed Round (April 6th, 2023).
Qdrant raised their $7.5 million Seed Round (April 19th, 2023).
Weaviate raised their $50 million Series B (April 21st, 2023).
And of course, Pinecone announced their $100 million Series B on April 27th.
With regards to product quality, team quality, capital raised, valuation, and (most importantly) traction, Pinecone remains a clear leader in the market. Let’s look at how both Pinecone the product and Pinecone the company have grown in the year since.
The Product
Pinecone’s userbase has grown dramatically in the past year.
At this time last year, Pinecone was serving several “thousands” of users, all accrued roughly within a year of launch.
Today, Pinecone has over 10,000 signups every day. Their core product — a vector database — has seen some major updates. These include:
High-throughput vector indexes. Pinecone’s vector indexes run on pods, pre-configured units of hardware optimized for either storage (s1) or throughput (p1). Pinecone’s next-generation p2 performance pods use a new graph-based index to achieve search speeds 10x faster than p1 and significantly higher throughput per replica (up to 200 queries per second). p1 and s1 pods were also upgraded to see 50% faster queries and higher throughput. Shipped 12/8/22.
Sparse-dense embeddings. Dense vectors have fewer values (100-1000), but nearly all of their values are non-zero. Sparse vectors have more values (i.e. 100,000), but nearly all of their values are zero. Sparse and dense vectors are used to represent different things (i.e. term-level importance vs semantic meanings), but it’s useful to query over both if you’re building something like hybrid lexical-semantic search or multimodal search. You couldn’t previously store both types in one database for performance reasons, but Pinecone’s new sparse-dense hybrid search technology has solved that problem. Shipped 2/23/23.
Vertical Scaling. Previously, an index growing above available capacity meant you had to scale horizontally by creating a new index with more pods and switching over manually, which took engineering time. Now, vertical scaling means you can grow your existing index up to 8x with zero downtime by adjusting the capacities of individual pods. Shipped 8/16/22.
Upgraded Free Plan. Storage-optimized s1 pods are now available on the free plan, giving users 5x greater capacity while trying Pinecone. Shipped 8/16/22.
Pinecone has also picked up some serious new customers: Klarna, HubSpot, Yelp, Bain, GoDaddy, Accenture, ClickUp, Zapier, Shopify, CVS, Midjourney, YCombinator, BambooHR, and Microsoft now all use the service.
A suite of new enterprise-facing features has made this possible:
SSO. Pinecone now supports a centralized access point, streamlined user management based on roles, and secure authentication methods.
Usage dashboards. A new usage dashboard allows developers to start projects, add team members, and view usage/spend without leaving the console. Users can break things down with filters by timespan, project, and service to visualize and predict future usage.
Multi-cloud support. Pinecone is now available for deployment on the GCP, AWS, and Azure marketplaces. For large customers, this helps to consolidate spend/billing while also reducing procurement time (i.e. licensing and configuration).
Integrations. A suite of new partnerships and integrations with popular tools (i.e. OpenAI, LangChain, Databricks, Datadog, TruLens, ElasticSearch) has made it easier for developers to integrate Pinecone.
The Company
The company itself has also grown significantly in the past year. Pinecone has maintained a high hiring bar and has managed to recruit some impressive new people. They include:
Bob Wiederhold - President and COO
Bob was previously CEO and Executive Chairman of Couchbase (NASDAQ: BASE). Before that, he was CEO of Transitive (acquired by IBM) and CEO of Tality, a design services and intellectual property company with $200M of revenue.
Elan Dekel - VP of Product
Elan was previously Product Lead for Core Data Serving at Google, where he was product lead for the indexing/serving systems powering Google search, YouTube search, Maps, Assistant, Lens, Photos, and more. Before that, he was Founder and CEO of Medico, which was acquired by Everyday Health.
Chuck Fontana - VP of Business Development
Chuck was previously SVP, Corporate & Business Development at SentinelOne (NYSE: S). Before that, he was VP, Corporate & Business Development at Okta and Director, Business Development & Product Marketing at Cisco.
Michael Proia - VP of Sales
Michael was previously Vice President Americas at Kong (last valued at 1.4 billion). Before that, he was Regional Vice President of Sales at Hortonworks.
Travis Donia - Director of Engineering
Travis was previously VP of Engineering at Clarivate (NYSE: CLVT). Before that, he was CTO/Head of Product at Context Matters, which was acquired by Clarivate.
Hien Phan - Head of Product Marketing
Hien was previously Director of Product Marketing at Amplitude (NYSE: AMPL). Before that, he was Director of Product Marketing at Mode Analytics, which was acquired by ThoughtSpot for $200 million.
Kyle Himmelwright - Director of Revenue Operations
Kyle was previously Head of Revenue Operations at Birdeye, which just crossed $100m ARR and 100,000 customers. Before that, he was Director of Revenue Operations at Yelp.
Amie Ernst - Director of Talent Acquisition
Amie was previously Global Talent Leader - Core Engineering at Goldman Sachs. Before that, she was a Senior Manager, Recruiting at Amazon Web Services.
The Future
As far as they’ve come, Pinecone still has a long way to go. AI is moving very quickly, and staying a market leader isn’t a given. To stay on top product-wise, Pinecone will have to keep executing along several axes:
Building a great database. At the center of everything, Pinecone can’t stop innovating on their core product - this means making it faster, more reliable, more flexible, and more efficient with improvements around indexing, scaling, querying.
Building a great service. One layer out, Pinecone can’t stop improving the developer experience, production readiness, and enterprise readiness that separates their managed offering from open-source ones. This means features around data management, metadata handling, security, compliance, and more.
Building a great ecosystem. Another layer out, Pinecone can’t stop nurturing the ecosystem that’s driven so much of their growth. This means continuing with integrations, partnerships, meetups, educational content, and community-driven events.
If they can keep it up, Pinecone’s future is promising.
Vectors are a cornerstone of machine learning because they’re how computers make sense of unstructured data (text, images, video). Caching and organizing them is how machine learning systems today maintain state between inference runs.
In other words, a long-term store for vectors is the closest thing AI systems today have to long-term memory.
Vector databases are long-term memory for AI.
Conclusion
Vectors are the universal input and output format for neural networks. Every image generated, chatbot queried, or forward pass ever started with someone converting their input into a vector. In a very real sense, vectors were the first data type native to machine learning.
Pinecone was the first database giving them the respect they deserved.
They’re (still) hiring.
If you’re interested in the investing side of things, our friends at NFX (the largest seed-stage fund in the world) are looking for a new member to join their investment team. Spending a few years at a venture firm can be a great launchpad for an operating career, especially if you have an engineering background. Learn more here.
In case you missed our previous releases, check them out here:
And to make sure you don’t miss any future ones, be sure to subscribe here:
Finally, if you’re a founder or investor with a company you think we should cover please reach out to us at ericzhou27@gmail.com and uhanif@stanford.edu - we’d love to hear about it :)