
Why You Should Join Modal
The future of GPUs is serverless.


Some opportunities to consider:
Modal has grown revenue >50x in the past year and has taken less than 18 months to reach an eight figure run rate. They’re currently hiring product and systems-focused software engineers in New York City.
Etched has built a chip that can run transformers >10x faster than GPUs. They’re currently hiring Machine Learning Researchers, Compilers Engineers, Verification Engineers, Firmware Engineers, RL Design Engineers, interns, and more in Cupertino.
Partnership: our friend Billy joined Rippling ($13B+) before its Series A. The best advice he ever got was to think like a VC when looking for a startup job, so he built a free tool to help others do the same. Prospect uses the same structures and data sources as the best data-driven VCs (i.e. Coatue, Tribe) to help candidates find the highest potential startups to join.
If you’re looking for more promising companies to join, we highly recommend checking them out.
Welcome to “Why You Should Join,” a monthly newsletter highlighting early-stage startups on track to becoming generational companies. On the first Monday of each month, we cut through the noise by recommending one startup based on thorough research and inside information we’ve received from venture firms we work with. We go deeper than any other source to help ambitious new grads, FAANG veterans, and experienced operators find the right company to join. Sound interesting? Join the family and subscribe here:
Why You Should Join Modal
(Click the link to read online).

At this point, you’re probably familiar with the important applications of generative AI.
The Chrome extension that’ll do your homework for you.
The app where you can reanimate dead celebrities.
The AI wingman for charming people on Tinder, the AI girlfriend for when things fall apart, and the AI therapist for when she eventually dumps you too.
You know, the game-changing stuff.
You might be surprised, then, that despite searches for “AI Girlfriend” being up 2400% last year, almost all the 1.3 trillion dollars generative AI will eventually generate is set to come from boring, enterprise-y things.
Assistants and productivity tools for white collar workers. Agents to write code and fix outages for software engineers. Copilot for Office 365, which over 60% of the Fortune 500 are already using.
Did you know that Accenture (the consulting firm) has already booked over $1 billion in Generative AI engagements?
That might be more than like every AI startup combined.

Ok, maybe you’re not surprised.
But if you’re like us, it’s a little disappointing.
A year and a half into generative AI, it’s worth asking — is the future of AI just big companies building copilots for existing products? What’ll it take for more AI-native apps and products to hit the mainstream?
Much has been written about the different paths and challenges here, but the small piece we’d like to explore today is around the accessibility of compute.
While access to cutting edge models has been democratized through open source, what hasn’t been is the infrastructure required to train and run them. For most hackers, GPU-based workloads (i.e. inference pipelines, training runs) still aren’t as accessible because of how difficult and expensive GPUs are to reserve, even for small amounts of time.
Most developers can’t justify reserving a large block of GPUs just to experiment with their own models or to prepare for production scale that may or may not come.

Of course, working around pricy instances is nothing new.
In the past, developers solved a similar problem with the concept of cloud functions - individually packaged pieces of code that could be scaled independently and automatically. Instead of renting a traditional server for a fixed rate (regardless of usage/idle time), offerings like AWS’s Lambda or GCP’s Firebase Functions would let you host code and pay per function call instead.
This paradigm would be particularly useful for GPU-based workloads. You can imagine how it would make working with AI more accessible, which is why there’s been strong demand for exactly this sort of product.
Unfortunately, none of the cloud providers have figured out how to build it.

Fortunately, the team at Modal has.
Background: The Landscape of ML Infrastructure
Before getting too deep into Modal, it’d probably be helpful to get a sense of the broader landscape they fit into. What is a “serverless GPU”, and how does it compare to all the other ML hosting solutions out there?
These days, there are lots of companies looking to make deploying and scaling machine learning models easier. Many of them — from GPU re-sellers to end-to-end models as a service — get bundled under the same general umbrella of “model hosting infrastructure”.
These products are all quite distinct, but their value propositions sound similar enough that it’s easy to get confused if you’re not technical.
At a high level, we’ve found it helpful to split companies and their offerings into three general categories, each operating at a different level of abstraction:
Companies that will host and autoscale a model for you.
Companies that will host and autoscale any piece of code for you.
Companies that will host hardware for you.
Models as a Service
Starting off at the highest level of abstraction, companies in this category will host and autoscale a model for you. They’ll expose a simple endpoint for your application to call, automatically scaling the model up and down to meet demand while avoiding wasted GPU time. These offerings often have large collections of community-published models you can call out-of-the-box — think text generation models (i.e. Llama 7B), image generation models (i.e. SDXL), or image restoration models (i.e. GFPGAN). In most cases, you end up paying per second of GPU time used.

Besides being the easiest way to run popular models, they’re also the easiest way to host a custom model. If you have a model’s weights and a script to run it, these services will package, deploy, and host the entire thing for you. For instance, when containerizing your model, Replicate’s Cog will automatically generate a FastAPI endpoint to call it and a queue worker to batch its requests.
Companies with offerings that fit in this category include Replicate, Baseten, BentoML, Mystic, Hugging Face’s Serverless Inference API, and AWS’s Sagemaker. While there are certainly nuances between these offerings (i.e. Sagemaker’s autoscaling endpoints require you to define your own scaling policy based on different utilization metrics, for a flat fee Mystic offers this functionality to companies using their own cloud), at a high level what’s being offered is an endpoint users can call without worrying about anything else.
Functions as a Service
Moving down one layer of abstraction, companies in this category will host and autoscale any arbitrary piece of code for you. Also known as “serverless”, offerings here let you upload a function and run it as a one-time script, a regularly scheduled cron job, or an endpoint/microservice that will automatically scale up and down to meet demand.
You can kind of think of this as a superset of the “model as a service” category, where you can run any workload (i.e. training models, scraping data, rendering teapots) and with wider variety of triggers while still only paying for the time your code is running. You generally won’t get pre-hosted models you can call out of the box, but you will get more control over the exact code that’s being autoscaled.
Like we mentioned earlier, serverless offerings have been around for a while. For CPU-based workloads, AWS’s Lambda functions, GCP’s Cloud Functions, and Azure’s Functions are all examples of offerings in the space. For GPU-based workloads, though, the paradigm is new: only a few startups have begun offering them in the past year, driven by demand from the rise of generative AI.
Companies with offerings that fit in this category include Modal, Beam and Inferless. We will go deeper into the differences between companies in this category later.
Hardware as a Service
At the lowest level of abstraction are companies that essentially rent out hardware. These companies provide “instances” (virtual machines) with specific parts (i.e. 8x A100s) that users can use for their application. Users are responsible for SSH’ing in to set up and run their workloads themselves, and they’re also responsible for acquiring more instances and distributing a workload if additional scale is needed. Generally, these instances are rented out on-demand or in advance for large blocks of time (i.e. by week, by month, by year). They’re the cheapest per hour, but you end up paying a fixed rate regardless of actual utilization.
This is the bread and butter of all the major cloud providers. AWS, GCP, Azure, Oracle, and IBM all have offerings in this category. The recent surge in GPU demand has also spawned a number of startups doing the same: Lambda Labs, Coreweave, Vast, and Brev are all players in this space as well.

Of course, there are still a number of companies that don’t fit neatly into one of the categories above. For instance:
Runpod has offerings in all three categories (a serverless offering, an endpoints service, and a way to rent entire instances).
TogetherAI sells instances (Together GPU Clusters) and also endpoints (Together Inference) for running popular open source models. In addition, they have a proprietary inference engine which makes running things faster and cheaper.
Foundry has an orchestration layer which dynamically splits workloads across instances based on factors like demand, capacity, and how long users are willing to wait.
Anyscale has both a platform letting users deploy Ray applications serverlessly and an endpoints offering competing directly with some of the companies mentioned above.
In a general sense, though, we’ve found this framework helpful in making sense of the large and growing number of companies in the ML hosting space.
If things are still fuzzy, here’s a small chart we made which simplifies things further:

Modal
So, Modal is a serverless GPU offering, meaning they host and autoscale GPU functions for users. Think of them as AWS Lambda, but with support for GPUs as well as CPUs.
With Modal, users can deploy an endpoint to run inference on Llama-70B, but they can also render a Blender scene, run a simulation, scrape data, or generate embeddings for a million different images before running a K-means clustering workload across all of them. Moreover, they can do so while paying per second of active CPU/GPU time.
Concretely, this creates value in a few ways:
Lower cost - developers don’t have to pay for time their machines are idle.
Better developer experience - developers don’t have to worry about provisioning, configuring, or scaling their workloads.

More than that, though, Modal has built the best serverless GPU offering on the market. Instead of building on Docker and Kubernetes, Modal’s system is powered by a custom serverless runtime, a custom file system, a custom image builder, and a custom job scheduler.
The superior performance this has enabled creates value in a few ways:
Lower cost - Modal’s faster scale-up times ultimately mean less idle time and lower costs for users.
Better developer experience - Modal’s lower cold start times mean a faster development loop, letting users run code on remote machines as if they were developing locally.

Modal launched publicly in October of last year and has grown swiftly ever since. Besides growing 50x in the past year and hitting an 8 figure run rate, they’re now doing more revenue each hour than they were doing all month just a year ago. Customers include large companies like Ramp and Scale, high profile startups like Cognition Labs, Suno, Cursor, and Substack, and other sizable entities we won’t reveal.
The company was founded in 2021 by Erik Bernhardsson and Akshat Bubna. Erik was previously CTO of Better.com and one of the first 30 employees at Spotify, where led their early data science/machine learning teams and built the core of their music recommendation systems. Akshat was previously a Staff Software Engineer at Scale, where he joined as an early employee after studying Computer Science and Mathematics at MIT. Both have a gold medal from the IOI.
On the back of their impressive team and traction, Modal raised a $16 million dollar Series A in October of last year led by Redpoint Ventures. Before that, they had raised a $7 million seed round led by Amplify Partners.

Modal has a remarkable team, a product developers love, and the ultimate vision to solve every engineer’s infrastructure problems, once and for all.
Will they be able to pull it off?
We think they’ve got a shot.
Let’s get into why.
The Opportunity
To understand whether Modal might be a good business, there are really two questions we have to answer:
Is there a large market for serverless GPU functions?
Does Modal have a shot at leading that market?
The Market for Serverless GPU Functions
Modal makes money when other companies run functions on their GPUs.
You probably don’t need to be persuaded that lots of people want to run code on GPUs - it’s why companies are spending so much on datacenter buildouts and why server providers are raising so much money. The real question is whether a sizable portion of these people want to do it in a serverless manner.
One helpful proxy here is how much people are spending on serverless CPU functions. If a lot of people are finding value in serverless CPU functions, it’s reasonable that a similar portion will find value in their GPU counterparts as well.
The numbers here are promising:
Today, over 70 percent of AWS customers, 60 percent of GCP customers, and 49 percent of Azure customers use one or more serverless solutions. Last year, serverless adoption for organizations running on Azure grew 6 percent, serverless adoption for organizations running on GCP grew 7 percent, and serverless adoption for organizations running on AWS grew 3 percent.
There have been a number of sizable companies built on vertical-specific applications of serverless functions — think Vercel and Netlify, both of which are serverless frontend/CDN offerings. 7 percent of organizations running serverless workloads are also using at least one of these emerging cloud platforms. Of these, 62 percent are using a frontend development platform like Vercel or Netlify and 39 percent are using an edge compute offering like Cloudflare or Fastly.
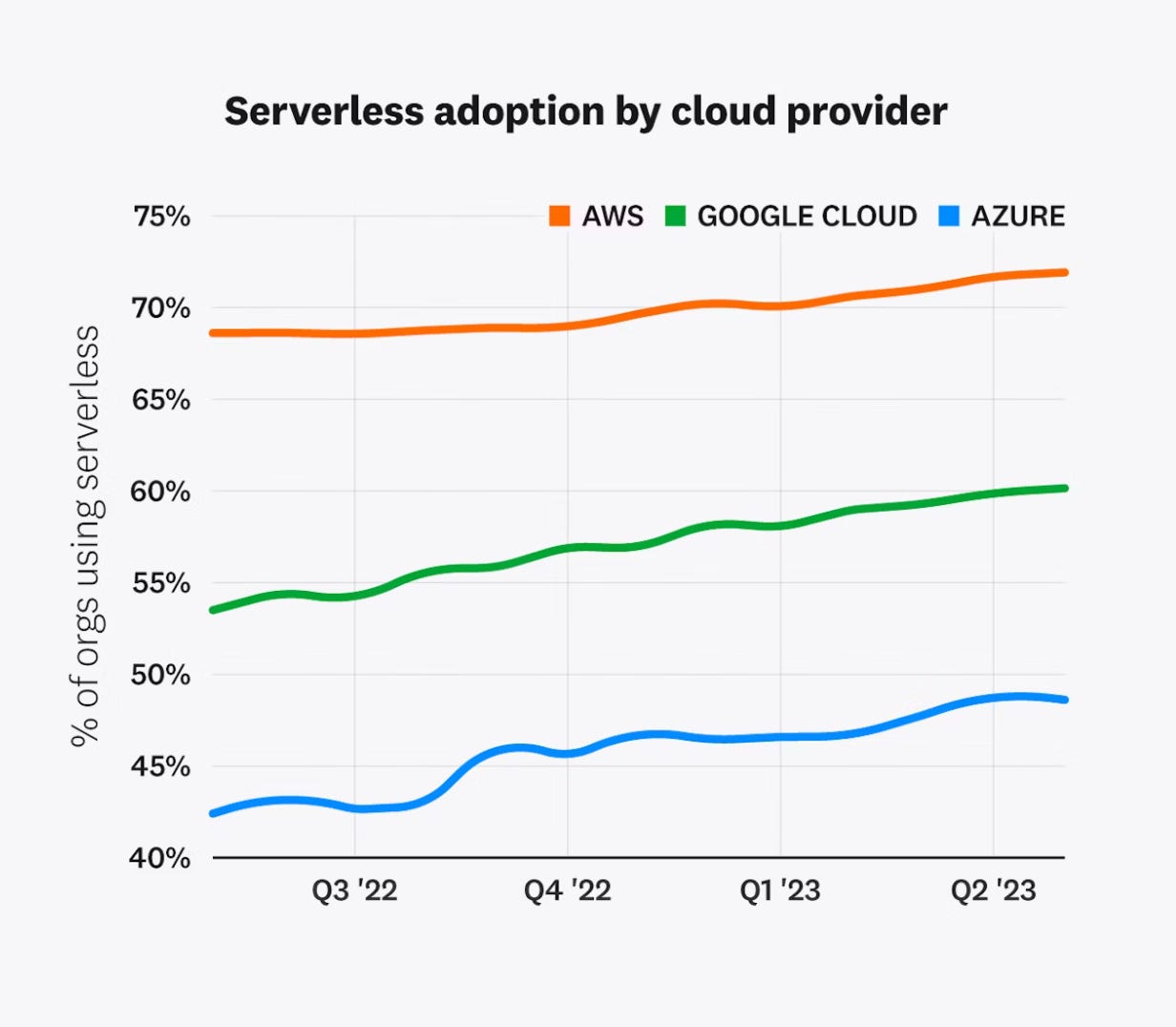
Since both general (i.e. AWS Lambda, Google Cloud Functions) and vertical-specific (i.e. Vercel, Netlify) versions of serverless functions have found meaningful adoption, we would guestimate that a meaningful number of companies would find the same benefits — easy scalability, built-in redundancy/uptime guarantees, generally better developer experience — attractive for their growing GPU/AI workloads as well.

If anything, we could expect the proportion to be even higher for GPU-based workloads:
GPU instances are more expensive than CPU instances. Idle time is more pricey, and the only way to avoid it is by using a serverless offering.
GPU instances are more supply-limited than CPU instances. It’s less likely you can rent a rack of them and provision more on the spot as you need to scale — for many companies, serverless will be their only option.
Modal’s early traction points to this being something developers have wanted for a while.
Modal’s Approach
So out of all the serverless GPU offerings out there, why do we like Modal’s the best?
Compared to its peers, Modal is better on two fronts: technology and developer experience.
Technology
Instead of using Docker and Kubernetes like most serverless offerings, Modal has built a custom serverless runtime, a custom file system, a custom image builder, and a custom job scheduler. Building everything from scratch has given their platform better performance — think lower cold start times, faster scale ups, and ultimately lower costs for users.
How does it all work?
For illustrative purposes, let’s explore an early, simplified version of Modal’s architecture.
When you run a containerized function on a remote machine, the worker usually begins by pulling down the container image you’ve picked. Once that’s done, it’ll start the container and run your function inside.
However, this process is pretty slow. Pulling down the image, especially the first time, can take a while — it involves downloading all the necessary files, dependencies, and configurations needed to run your app. This includes a lot of stuff, much of which isn’t needed at runtime — containers often contain a lot of bloat!

To get around this, Modal has built what’s essentially lazy loading for files within container images.
Early on, they would take their users’ images and put them on NFS - a distributed file system protocol which lets clients access files over networks as if they were stored locally. Then, instead of pulling the container image in its entirety before running it, worker machines connected to NFS could simply use runc - a Docker subroutine which launches a container from an arbitrary directory - to run said container from it’s image’s location on NFS directly. Since NFS makes it as if all the necessary files are already on the worker’s machine, runc is able to proceed. The files get fetched as needed under the hood (handled by the NFS protocol), something which helps prevent much of the bloat from getting downloaded.
To address the remaining latency this introduces (i.e. when starting a container, reading each required file over NFS now takes several milliseconds), Modal has built a custom filesystem which makes significant usage of caching.
See, container images have a lot of overlap:

Modal has built a content-addressable filesystem which stores each unique file just once — even if it’s being used across thousands of different containers and stored at thousands of different locations.
Besides being better from a storage point of view, this structure makes caching easier as well. When runc needs a file, Modal maps the requested filepath (i.e. /lib/x86_64-linux-gnu/libc-2.31.so) to a hash of the requested file’s contents, which serves as the address of the original file. Then, if the file hasn’t been cached on local disk already, it’s fetched (either from Modal’s file server or some remote, external server if it’s completely new) and returned before being cached for the next run. If it’s already there, it’s returned immediately.
Since there’s so much overlap between unrelated images, there’s a good chance that by the time you run your function, a prior run (by a completely different user) will have resulted in your worker caching most of the files your container needs. This minimizes the necessary reads over NFS, which cuts down on latency even further.

Now, there are a number of deeper implementation details we won’t go into here. For instance, how does the filesystem and its index get updated? What if the container image doesn’t already exist on NFS? If you’re interested in learning more, there’s a great talk Erik gave on this topic, much of which we’ve tried to summarize here.
The upshot, however, is that Modal containers have much faster start times than Docker containers:
Using runc + NFS to get around downloading the entire image means files are lazy-loaded — only what’s used in the actual function is downloaded onto the worker machine.
Files are cached on worker machines across containers and across container runs, so when files are needed they can often be accessed right away. Caching by file is a lot more granular than caching by layer, which is what Docker does out of the box.
Modal has since optimized their system a lot more. For instance, they now have a custom protocol where instead of using NFS, they serve blobs using Cloudflare’s R2 service. Instead of hacking things with runc, they use gvisor, which is generally more secure. They’ve also made a number of optimizations to make subsequent (not just initial) startup times faster - think storing "traces" of workloads and prefetching data that’s likely to be read, snapshotting CPU memory, etc.
The result is the same: every time you spin up a new container on one of Modal’s thousands of machines - either because you’re developing and want to test something or because you’re serving and need to scale - that container will come up much faster than if you were somewhere else. This is important not just for cost or performance, but also, as we’ll see, for ensuring the best possible developer experience.
Developer Experience
Modal’s core technology, the feature set they’ve built around it, and the platform they’ve built on top of it have collectively enabled a better developer experience than anything else we’ve seen. There are a few reasons behind this:
For certain users, Modal’s core technology (quickly spinning up a container and running a function in it) enables a uniquely efficient development loop. Developers working on data-heavy applications often find it hard to work locally — local environments are usually different than the cloud environments their work will be productionized in (i.e. different hardware constraints), so developers who work locally often find themselves with confusing deployment issues and a great deal of re-written code. As a result, many data teams follow some version of the following remote development loop: they’ll build a container, push it, trigger the job, and download the logs for debugging purposes after. This process can take minutes to hours each time and can be a real pain. In contrast, with modal run it takes less than a second to spin up a container and run your code on a remote machine with the right environment and hardware. This compresses that loop into something as efficient as developing locally.
When it comes to feature completeness — out-of-the-box support for typical features and integrations — Modal is just more mature than everything else. For instance, beyond the basics they also support websockets, concurrent inputs on a single container, streaming endpoints, tunnels (live TCP ports), mounts for cloud buckets, and more.
As a platform and business, Modal is also the easiest to work with. They have the most generous free tier. They were the first to offer support for H100s. Even on customer service, their response time on Slack is unparalleled. It’s not often that the CEO and CTO are supporting individual developers late at night, but we’ve seen their team’s commitment ourselves:

Akshat is Modal’s Co-founder/CTO. Impressive response time for 11pm ET on a Monday night!

The common thread we’ve noticed across all this is a general commitment to craftsmanship and polish. We’ve seen this in everything Modal has built — from their core technology/documentation/APIs down to their support philosophy/error messages/blog post visuals. They clearly care a lot about what they’re building and are willing to take the time and effort to do it right, even if it’s not always the easiest path forward.
This is particularly rare in infrastructure companies, and something we admire deeply.
Competitive Landscape
Now that we have a deeper understanding of Modal’s strengths as a product and company, let’s take a deeper look at how they compare against other “function-as-a-service” offerings.
Runpod Serverless
Runpod is a platform which offers endpoints-as-a-service, functions-as-a-service, and instances-as-a-service. They recently raised a 20 million dollar seed round from Dell Technologies Capital and Intel Capital. Runpod Serverless, their functions-as-a-service offering, competes directly with Modal.
In comparing the two products, our overall impression (as users) was that Modal had a better product and developer experience.
Tech-wise, to our knowledge Runpod only supports Docker images, which suffer from the cold start problems discussed above. Modal has addressed this with a custom stack while maintaining compatibility with Docker-based workflows: while Modal uses a custom container builder, they have a custom implementation of the Dockerfile specification which allows developers to use environments previously defined in that manner.
From a DX perspective, Runpod is also a bit harder to work with. If you don’t already have a Docker image you’d like to use, its on you to define and push it to the container registry before getting started. In contrast, Modal doesn’t require any infrastructure at all — users just create an account, install the modal Python package, and set up a token. They can then start running jobs right away.
Beyond that, Runpod Serverless doesn’t have a free tier, making it more difficult for people to try. They also don’t support some of the more advanced features that Modal does (i.e. job scheduling).

Beam
Like Modal, Beam is a platform which only offers functions-as-a-service. The company (formerly known as Slai) raised a 3.5 million dollar Seed Round led by Tiger Global in 2022.
From a technical perspective, Modal and Beam are actually quite similar: Beam also has a distributed file system (they’ve stuck with NFS), a custom image format, and a content-addressable storage system, all of which they built this past summer.
However, we found Beam’s offering to be generally less mature than Modal’s — they’re still missing many of the features, integrations, and compliance-related checkmarks most serious and production-facing developers would expect.
For instance, to our knowledge you can’t build a Beam container from a Dockerfile like you can with a Modal container. Beam doesn’t support concurrent inputs within containers, streaming endpoints, or the ability to expose live TCP ports on containers. Beam isn’t SOC2 compliant like Modal is, they don’t offer integrations (i.e. with Vercel or Okta) like Modal does, and they don’t have any H100s like Modal does. Worst of all, they require a credit card to try their product.
The upshot is that if you were an early employee, investor, or customer picking between the two, it’s not clear why you wouldn’t just go with Modal.
Inferless
Inferless is an Indian platform which only offers functions-as-a-service. The company was founded in 2019 and is backed by Peak XV (formerly Sequoia Capital India). The product remains in private beta — you have to join a waitlist to get access.
While we haven’t tried their product, their documentation suggests a platform that’s generally less mature than Modal’s. For instance, they don’t support streaming endpoints, scheduled jobs, or H100s.
Hyperscalers
If you’ve gotten this far in the piece, there’s probably one big question still lurking at the back of your head:
Why haven’t GCP, AWS, or Azure built this already?
The hyperscalers pioneered the concept of functions as a service, and they have the world’s largest supply of GPUs — it only makes sense that they’d move into this market.
While we can only speculate, there are two likely reasons they haven’t yet:
Virtualization challenges. Exposing GPUs to short-lived, ephemeral VMs is not trivial technically. Each serverless function may have different GPU resource requirements, and allocating GPU resources dynamically while ensuring optimal utilization/performance is challenging. In addition, a serverless platform needs to ensure compatibility between GPU drivers, runtimes, and the underlying virtualization layer. Different GPU models and architectures may have specific driver requirements, and maintaining compatibility across different serverless instances can be challenging.
Security and isolation challenges. Ensuring strict data isolation between serverless functions executing on the same physical GPU, mitigating side-channel attacks that might exploit shared GPU resources, and managing access control and permissions for serverless functions accessing GPUs are all non-trivial technical challenges.
Modal has worked hard to address many of these issues, and they have a head start as a result.
Ultimately though, it’s probably only a matter of time before the hyperscalers release competing offerings of their own.
When they do, though, it’s not a guarantee that their offering will be as performant or well-crafted as the platform Modal has built. Modal has always focused on developer experience, something which the hyperscalers don’t have the best track record with.


Team
Modal’s long-term vision is to build the world’s best serverless platform. They want to abstract away every developer’s challenges with infrastructure. In the same way the cloud allowed people to get around buying and hosting physical servers, Modal envisions a world where they can do the same with the instances we all use today.
To put it another way, Erik told us his ambition is to someday replace Kubernetes.
It’s a bold vision. If anyone’s going to pull it off, though, it’ll probably be this team. Modal’s first 7 employees had 5 IOI gold medals between them — consider a sampling of their roster.
Erik Bernhardsson - Co-Founder, CEO
Erik was previously CTO of Better.com. Before that, he was one of the first 30 employees at Spotify, where he led their early data science/machine learning teams and built the core of Spotify’s music recommendation systems.
Akshat Bubna - Co-Founder, CTO
Akshat was previously a Staff Software Engineer at Scale AI, where he joined shortly before their Series B. He holds a degree in Computer Science and Mathematics from MIT.
Jonathan Belotti - Software Engineer
Jonathan was previously Team Lead for the Data Platform at Canva. Before that, he was a Software Engineer at Zendesk. He holds a BS in Computer Software Engineering from RMIT and an MS in Mathematics and Statistics from the University of Technology Sydney.
Michael Waskom - Software Engineer
Michael was previously a Staff Machine Learning Scientist at Flatiron Health. Before that, he was a Research Scientist at NYU. He began his career as a Doctoral Researcher at Stanford, where he holds a PhD in computational psychology.
Eric Zhang - Software Engineer
Eric was previously a Software Engineer at Convex, where he was their first engineering hire. Before that, he was a Quant Research Intern at Jump Trading. He started his career as a Software Engineering Intern at Scale, and he holds a BA and MS in Computer Science from Harvard.
Irfan Sharif - Software Engineer
Irfan was previously a Software Engineer at Cockroach Labs. Before that, he was an ML Infrastructure Engineering Intern at LinkedIn. He holds a B.A.Sc. in Electrical and Computer Engineering from the University of Waterloo.
Ro Arepally - Software Engineer
Ro was previously a Tech Lead at Asana. Before that, he was a Software Engineer at RedCircle. He started his career as a Software Engineer at Uber, and he holds a BS in Mathematics from CMU.
Elias Freider - Software Engineer
Elias was previously the Analytics Data Lead at Kry. Before that, he was Co-Founder of EdQu, an edtech startup. He began his career as an Analytics Software Engineer at Spotify and holds an MS in Computer Science from the KTH Royal Institute of Technology.
Daniel Norberg - Software Engineer
Daniel was previously a Senior Staff Engineer at Spotify. Before that, he was a Software Engineer at Treasure Data. He holds an MS in Computer Science from the KTH Royal Institute of Technology.
Staffan Gimåker - Software Engineer
Staffan was previously a Senior Software Engineer at Detectify. Before that, he was a Senior Software Engineer at Spotify. He holds a BS in Computer Engineering from the KTH Royal Institute of Technology.
Richard Gong - Software Engineer
Richard was previously a Software Engineering Intern at Scale AI, a Trading Intern at Jane Street, and a Perception Intern at Cruise. He holds a BS in Electrical Engineering and Computer Science from MIT.
Margaret Shen - Head of Business Operations
Margaret was previously an Associate at Accel. Before that, she was a Product Manager at OakNorth and Dropbox. She holds an MBA from HBS and a BS in CS from Stanford.
Rachel Park - Software Engineer
Rachel was previously a Software Engineering Intern at Warp. Before that, she was a Software Engineering Intern at Mem. She holds a BS in CS from Stanford.
Sona Dolasia - Design
Sona was previously a Senior Product Designer at Scale AI. Before that, she was a Product Designer at Spotify. She holds a BA in Cognitive Science from UC Berkeley, where she was a Regents Scholar.
Conclusion
Working with GPUs is expensive and challenging today, but it won’t be if Modal succeeds.
One can but imagine the wave of industry-defining, category-creating, entrepreneurial activity this will unleash.
The John D. Rockefeller of AI girlfriends is out there somewhere, and he’s been waiting for a platform like Modal to build upon.
They’re hiring.
In case you missed our previous releases, check them out here:
And to make sure you don’t miss any future ones, be sure to subscribe here:
Finally, if you’re a founder, employee, or investor with a company you think we should cover please reach out to us at ericzhou27@gmail.com and uhanif@stanford.edu - we’d love to hear about it :)
These breakdown are incredible. Insight into amazing companies and how each fits into its industry and stacks up against the competition.